面向云计算的数据中心发展正是如火如荼。
在实践应用中,各个企业和云服务提供商都碰到了若干类似的问题,简单总结一下。
1 带宽保证
保证数据中心中点对点的无阻塞大容量的带宽。特别是横向流量。传统的以太网采用STP技术,极大限制了带宽资源的供应。这方面目前的解决方案,主要是融合3层的多路经技术,包括Cisco主推的TRILL标准(FabricPath核心技术),和IEEE主推的802.1aq标准(SPB)。
2 低延迟
保证任意两点之间低延迟的互通。这往往跟高带宽矛盾,因为如果采用了3层路由来实现多路经转发,自然会加大网包转发处理的复杂度(包括加减包头,计算等),造成延迟增大。因此,要在保证高带宽的前提下,还能实现低延迟,需要通盘的设计考虑。这方面的技术方案主要有Juniper主推的QFabric,号称实现点到点只有1跳转发,延迟低于5us。
3 虚拟化
包括计算资源虚拟化,存储资源虚拟化和网络资源虚拟化。前两者有大量的成熟方案,包括VMware、EMC和IBM等。对于网络资源虚拟化,目前还处在探讨和摸索阶段。主要有两个问题,一个是如何让vm接入网络,即让网络感知到vm的存在。这方面的工作包括Cisco Nexus 1000v中采用的VN-link技术,Vmware的Vcenter,Xen的Xenserver等。基本都是各家处于自身考虑,设计的私有机制。
另一个问题是如何实现网络在各层,特别是2层的虚拟化。传统Vlan仅仅支持最多4094个segment,而且扩展性差。今年8月份由Vmware和Cisco等提出的VXLAN草案,采用在3层以上搭建overley2层网络的方案,支持2^24个segment,在某种程度上能缓解vlan的缺陷。
4 管理性
数据中心中的资源复杂,特别网络架构与传统的网络不同。在引入大量的虚拟化和其他机制后,通过网络资源来协调整合计算和存储资源,对外统一提供虚拟的云资源,其复杂度要远远超越普通企业网的管理复杂度。无法管理,则意味着云计算只能是纸上谈。这方面包括Xenserver、Openstack都在做一些有意的尝试,但目前还远未到成熟可用的时候。
Wednesday, December 28, 2011
Monday, December 26, 2011
也谈谈TRILL
TRILL最近很火。
最早在09年的时候,就有rfc提出来,要设计一个新的协议,改进现有STP的种种问题。11年小半年时间更是连发了5个rfc出来讨论TRILL的设计和应用(6325-6327,6361,6439)。
可能有对网络不太熟悉的同学,先来介绍下STP。
STP是Spanning Tree Protocol的缩写。我们知道对于现在的局域网(LAN)来说,交换机是实现多个节点互相通信的基础。而想要连接多个LAN,就需要交换机之间能有一定的机制来互通。如果交换机拓扑中含有环,那么就可能会出现循环转发,整个网络也就容易挂掉。因此,被称为“互联网之母”的Radia Perlman大妈就跳出来设计了个STP,还因此开心的写了一首小诗。
I think that I shall never see
A graph more lovely than a tree.
A tree whose crucial property
Is loop-free connectivity.
A tree that must be sure to span
So packets can reach every LAN.
First, the root must be selected.
By ID, it is elected.
Least-cost paths from root are traced.
In the tree, these paths are placed.
A mesh is made by folks like me,
Then bridges find a spanning tree.
其实STP的理念十分简单,拓扑中有环存在不是么?我禁掉其中的某些链路,自然就没有环了(当然要具体实现还需要很多的机制和协议)。STP因为其简洁有效,成为了事实上二层网络互通的标准。当然,凡事都会有利有弊,STP的问题主要有两点,一个是仅仅用了某些链路,很可能降低网络的性能;另一个是一旦出现链路故障,重新计算STP收敛不够快。
也正是为了解决这两个问题,Radia Perlman和其他的一些专家一同又提出了TRILL。
TRILL的设计理念也十分明确,把二层和三层各自的优点都结合起来,设计一个新的2.5层的协议出来。总的想法是在每个二层网络内部用传统的二层,而在各个交换机之间采用类似三层路由的机制,来实现多路径和快速收敛等。
TRILL的提出,为实现大规模的二层网络和保持高性能的互通带来了曙光。而现代云计算数据中心的发展,更是在这两方面提出了很强的需求,这也是为何TRILL在近些年讨论的越来越多,并被Cisco等支持,还作为其面向下一代数据中心核心网络技术FabricPath中的核心技术。
话说在TRILL的rfc6325中,Radia大妈又写了一首小诗。
I hope that we shall one day see
A graph more lovely than a tree.
A graph to boost efficiency
While still configuration-free.
A network where RBridges can
Route packets to their target LAN.
The paths they find, to our elation,
Are least cost paths to destination!
With packet hop counts we now see,
The network need not be loop-free!
RBridges work transparently,
Without a common spanning tree.

最早在09年的时候,就有rfc提出来,要设计一个新的协议,改进现有STP的种种问题。11年小半年时间更是连发了5个rfc出来讨论TRILL的设计和应用(6325-6327,6361,6439)。
可能有对网络不太熟悉的同学,先来介绍下STP。
STP是Spanning Tree Protocol的缩写。我们知道对于现在的局域网(LAN)来说,交换机是实现多个节点互相通信的基础。而想要连接多个LAN,就需要交换机之间能有一定的机制来互通。如果交换机拓扑中含有环,那么就可能会出现循环转发,整个网络也就容易挂掉。因此,被称为“互联网之母”的Radia Perlman大妈就跳出来设计了个STP,还因此开心的写了一首小诗。
I think that I shall never see
A graph more lovely than a tree.
A tree whose crucial property
Is loop-free connectivity.
A tree that must be sure to span
So packets can reach every LAN.
First, the root must be selected.
By ID, it is elected.
Least-cost paths from root are traced.
In the tree, these paths are placed.
A mesh is made by folks like me,
Then bridges find a spanning tree.
其实STP的理念十分简单,拓扑中有环存在不是么?我禁掉其中的某些链路,自然就没有环了(当然要具体实现还需要很多的机制和协议)。STP因为其简洁有效,成为了事实上二层网络互通的标准。当然,凡事都会有利有弊,STP的问题主要有两点,一个是仅仅用了某些链路,很可能降低网络的性能;另一个是一旦出现链路故障,重新计算STP收敛不够快。
也正是为了解决这两个问题,Radia Perlman和其他的一些专家一同又提出了TRILL。
TRILL的设计理念也十分明确,把二层和三层各自的优点都结合起来,设计一个新的2.5层的协议出来。总的想法是在每个二层网络内部用传统的二层,而在各个交换机之间采用类似三层路由的机制,来实现多路径和快速收敛等。
TRILL的提出,为实现大规模的二层网络和保持高性能的互通带来了曙光。而现代云计算数据中心的发展,更是在这两方面提出了很强的需求,这也是为何TRILL在近些年讨论的越来越多,并被Cisco等支持,还作为其面向下一代数据中心核心网络技术FabricPath中的核心技术。
话说在TRILL的rfc6325中,Radia大妈又写了一首小诗。
I hope that we shall one day see
A graph more lovely than a tree.
A graph to boost efficiency
While still configuration-free.
A network where RBridges can
Route packets to their target LAN.
The paths they find, to our elation,
Are least cost paths to destination!
With packet hop counts we now see,
The network need not be loop-free!
RBridges work transparently,
Without a common spanning tree.
让人不得不赞叹,大妈真是个人才(随便搜搜大妈的简历,就知道大妈功力之深厚)。
附:Radia大妈照
Sunday, December 11, 2011
关于SDN和未来云计算数据中心的报告
昨天,在首届SDN和数据中心技术研讨会上,我做了一个报告,给与会的各位专家介绍SDN相关技术和其在新一代数据中心中的应用,以及我对未来云计算发展方向的展望。
在报告中主要提出两个核心的理念。
一是关于信息技术从性能阶段往智能阶段的转变。
人类文明的发展,基础是对各种新技术的应用。而对任何新技术的应用大体可以分为两个阶段。第一阶段是简单依赖新技术变革带来的生产力飞跃,是一种粗放式的增长模式,可以称为性能主导阶段。而这种粗放式的模式必定会碰到瓶颈。一方面是对技术自身潜力的挖掘总有限制,在性能主导阶段,性能提升的代价必然是越来越大的,到了后面,这种代价可能已经超越了性能提升本身带来的收益。再一方面是人对新技术的需求,是越来越多的,简单的性能增长并不能满足所有需求。因此,过了性能主导阶段,必然会寻求一种更为精细化的阶段,可以称为智能主导阶段。以印刷术为例,开始是整版印刷,工人不断提升刻板速度,改进版面质量,但很快就变得难以继续提升了。这个时候就需要向智能化方向发展——活字印刷也就出现了。往往,在智能化阶段,孕育着更新一代技术的种子。此前的时期石器时代到电气时代,无不如此。而现在的信息时代,实际上已经到了性能主导阶段的后期,社会对智能化的需求也来越强烈。从生活中,我们也可以慢慢体会到这点。nokia破落,iphone大卖;汇编绝迹,C#盛行;pc收缩,平板兴起;甚至手动档已经越来越少见,自动档越来越流行,都证明了这点。这些年云计算的流行、社交网络、移动应用的兴起,也都是因为这个原因。所以,我预言,智能相关技术,特别是人工智能,春天已经到来了。而SDN的相关技术,恰好是智能化网络的一个很好的例子。
另外一个观点就是对于未来云计算数据中心的发展方向。
这个问题我也多次想过,这次算是有了个比较清晰的想法。我认为,未来的数据中心至少要具备两个基本特征。一是必须是性能(带宽、延迟)与智能(绿色、管理、配置、可靠、安全)需求都要能满足。二是必须是实现真正的完全虚拟化。当前的数据中心,其实并没有实现完全的虚拟化,无论提供的是iaas,paas,还是saas,都是针对用户的需求进行了深度的定制。一个提供saas的datacenter,很难同时服务需要其他xaas的用户。这个问题出在哪里?就出现在网络上,因为datacenter中的三个基本元素,计算、存储、网络,前两者的虚拟化都已经实现,唯独网络的虚拟化,最近几年才开始相关研究。未来的datacenter中,所有的资源,不论是什么类型,都应该统一的虚拟化,为“虚资源”。用户需要什么样的服务,就用这些“虚资源”组织起来,满足成能满足用户需求的形式。
以上两点想法,不知道是否是由我最早提出来的,但我坚信,都会被逐渐证实。
在报告中主要提出两个核心的理念。
一是关于信息技术从性能阶段往智能阶段的转变。
人类文明的发展,基础是对各种新技术的应用。而对任何新技术的应用大体可以分为两个阶段。第一阶段是简单依赖新技术变革带来的生产力飞跃,是一种粗放式的增长模式,可以称为性能主导阶段。而这种粗放式的模式必定会碰到瓶颈。一方面是对技术自身潜力的挖掘总有限制,在性能主导阶段,性能提升的代价必然是越来越大的,到了后面,这种代价可能已经超越了性能提升本身带来的收益。再一方面是人对新技术的需求,是越来越多的,简单的性能增长并不能满足所有需求。因此,过了性能主导阶段,必然会寻求一种更为精细化的阶段,可以称为智能主导阶段。以印刷术为例,开始是整版印刷,工人不断提升刻板速度,改进版面质量,但很快就变得难以继续提升了。这个时候就需要向智能化方向发展——活字印刷也就出现了。往往,在智能化阶段,孕育着更新一代技术的种子。此前的时期石器时代到电气时代,无不如此。而现在的信息时代,实际上已经到了性能主导阶段的后期,社会对智能化的需求也来越强烈。从生活中,我们也可以慢慢体会到这点。nokia破落,iphone大卖;汇编绝迹,C#盛行;pc收缩,平板兴起;甚至手动档已经越来越少见,自动档越来越流行,都证明了这点。这些年云计算的流行、社交网络、移动应用的兴起,也都是因为这个原因。所以,我预言,智能相关技术,特别是人工智能,春天已经到来了。而SDN的相关技术,恰好是智能化网络的一个很好的例子。
另外一个观点就是对于未来云计算数据中心的发展方向。
这个问题我也多次想过,这次算是有了个比较清晰的想法。我认为,未来的数据中心至少要具备两个基本特征。一是必须是性能(带宽、延迟)与智能(绿色、管理、配置、可靠、安全)需求都要能满足。二是必须是实现真正的完全虚拟化。当前的数据中心,其实并没有实现完全的虚拟化,无论提供的是iaas,paas,还是saas,都是针对用户的需求进行了深度的定制。一个提供saas的datacenter,很难同时服务需要其他xaas的用户。这个问题出在哪里?就出现在网络上,因为datacenter中的三个基本元素,计算、存储、网络,前两者的虚拟化都已经实现,唯独网络的虚拟化,最近几年才开始相关研究。未来的datacenter中,所有的资源,不论是什么类型,都应该统一的虚拟化,为“虚资源”。用户需要什么样的服务,就用这些“虚资源”组织起来,满足成能满足用户需求的形式。
以上两点想法,不知道是否是由我最早提出来的,但我坚信,都会被逐渐证实。
Wednesday, November 23, 2011
从数楼层问题到最大熵原理
先来看一道智力题目。
有2个鸡蛋和100层楼。可以站在某层往下扔鸡蛋,问尝试多少次,可以一定能获知在哪一层的时候刚好让鸡蛋碎。
——————分割线,请先自行思考30s————————
初看此题,可能认为答案是100。很自然,挨着试呗。
我们假设第k层(k=1...100)的时候鸡蛋刚好碎,那么从第一层开始依次往上是最保险的。因为一旦一开始某次尝试的楼层>k,则鸡蛋碎掉。
当我们手头只有一个鸡蛋的时候,确实只能采取这种方法,因为我们不知道k,不能去冒险。但是,现在有2个鸡蛋,能否减少尝试的次数?
毫无疑问,肯定是可以减少的,比如我们在第50层扔下来第一个鸡蛋,如果碎了,说明k<=50,然后从1...49挨着试第二个即可,最多需要50次(1次第一个,49次第二个)。如果第一个鸡蛋没碎,说明k>50,再用这两个鸡蛋尝试剩下的51...100楼层即可。
那么最优解是多少呢?
仔细思考这个问题,我们尝试扔鸡蛋有两种方法,一种是可以冒险猜一层,一种是挨着保险的线性尝试。对于第一个鸡蛋来说,冒险或者保险都可以。问题在于,一旦第一个鸡蛋碎了,则我们手头就只剩下一个鸡蛋了,这个时候就不能冒险了,只能采取保险的线性方法。因此,关键在于第一个鸡蛋应该采取什么样的策略?冒险还是保险?
——————分割线,请再自行思考30s————————
先暂时把刚才的问题放到一边,我们来看“最大熵原理”。
“最大熵原理是在1957 年由E.T.Jaynes 提出的,其主要思想是,在只掌握关于未知分布的部分知识时,应该选取符合这些知识但熵值最大的概率分布。”
这段话来自百度百科,未必是最准确的定义,但意思已经讲透了。熟悉信息论的同仁相比已经理解了。
用大白话解释这段话,就是说,如果我们不知道足够多的信息,那么对于不知道的部分应该采取最保守的策略,不能添加任何的先验预测。
或者更直白点,如果不知道,千万不要蒙。
一个很平凡的例子就是掷骰子。假如实现你对这个骰子一无所知,请问它掷的结果该是什么样子的?很显然,大家都会说,六个面概率一样,肯定都是1/6.
那么现在告诉你它掷出来1的概率是1/2,那么结果是啥?因为我们只知道1的概率,对其他面依然一无所知,所以,六个面的概率只能是(1/2,1/10,1/10,1/10,1/10,1/10),即剩下的五个面应该是彼此均匀等价的。
回到我们的问题,我们在扔第一个鸡蛋的时候,假如我们选择了第N层作为第一次扔的层数,则有两个可能:
N >= k: 鸡蛋1碎,鸡蛋2可以线性查找1...N-1层,一共需要1+N-1=N次。
N<k: 鸡蛋2没有碎,我们在N+1...100层中解决同一个问题,但是扔的次数少了1.
按照最大熵原理,因为我们不知道任何事先的信息,这两种选择的概率都是等价的,我们要求得最优,就只能让它俩带来的代价一致,也即我们应当选择N,使得无论那种情形发生,我们最终的尝试次数都是一致的。
对于N >= k的情况,一共需要N次,所以对于N<k的情况一共也必须是N次才成。则我们在N+1...100中解决问题,所尝试的次数应当为N-1,此时我们已经成功排除了N层.
可以观察到类似的决策中,从第一次到第N次,我们依次排除了N, N-1, ...1层。
所以我们有
N+N-1+...+1 = 100,或者
N(N+1)/2 =100
容易求得N=14
就是按照这样一个平凡的基本原理,我们求出了这个问题的最优解。实际上,从最大熵原理出发,可以推出近现代信息学上一堆著名的公式和方法,比如大名鼎鼎的卡尔曼滤波器,比如人工智能中的语义分析。或许,越是简单自然的东西,越能反映出这个世界终极的秘密吧。
备注:
这道问题是一个朋友出给我的,我想了大约一分钟,就想透了其中的关键。问题本身并不难,但其解决思路却蕴含了一个基本的原理——最大熵。这或多或少让我感到意外和惊喜。
扩展思考,
一般的,如果我们手头有m个鸡蛋,去尝试n层楼,需要试多少次?
有2个鸡蛋和100层楼。可以站在某层往下扔鸡蛋,问尝试多少次,可以一定能获知在哪一层的时候刚好让鸡蛋碎。
——————分割线,请先自行思考30s————————
初看此题,可能认为答案是100。很自然,挨着试呗。
我们假设第k层(k=1...100)的时候鸡蛋刚好碎,那么从第一层开始依次往上是最保险的。因为一旦一开始某次尝试的楼层>k,则鸡蛋碎掉。
当我们手头只有一个鸡蛋的时候,确实只能采取这种方法,因为我们不知道k,不能去冒险。但是,现在有2个鸡蛋,能否减少尝试的次数?
毫无疑问,肯定是可以减少的,比如我们在第50层扔下来第一个鸡蛋,如果碎了,说明k<=50,然后从1...49挨着试第二个即可,最多需要50次(1次第一个,49次第二个)。如果第一个鸡蛋没碎,说明k>50,再用这两个鸡蛋尝试剩下的51...100楼层即可。
那么最优解是多少呢?
仔细思考这个问题,我们尝试扔鸡蛋有两种方法,一种是可以冒险猜一层,一种是挨着保险的线性尝试。对于第一个鸡蛋来说,冒险或者保险都可以。问题在于,一旦第一个鸡蛋碎了,则我们手头就只剩下一个鸡蛋了,这个时候就不能冒险了,只能采取保险的线性方法。因此,关键在于第一个鸡蛋应该采取什么样的策略?冒险还是保险?
——————分割线,请再自行思考30s————————
先暂时把刚才的问题放到一边,我们来看“最大熵原理”。
“最大熵原理是在1957 年由E.T.Jaynes 提出的,其主要思想是,在只掌握关于未知分布的部分知识时,应该选取符合这些知识但熵值最大的概率分布。”
这段话来自百度百科,未必是最准确的定义,但意思已经讲透了。熟悉信息论的同仁相比已经理解了。
用大白话解释这段话,就是说,如果我们不知道足够多的信息,那么对于不知道的部分应该采取最保守的策略,不能添加任何的先验预测。
或者更直白点,如果不知道,千万不要蒙。
一个很平凡的例子就是掷骰子。假如实现你对这个骰子一无所知,请问它掷的结果该是什么样子的?很显然,大家都会说,六个面概率一样,肯定都是1/6.
那么现在告诉你它掷出来1的概率是1/2,那么结果是啥?因为我们只知道1的概率,对其他面依然一无所知,所以,六个面的概率只能是(1/2,1/10,1/10,1/10,1/10,1/10),即剩下的五个面应该是彼此均匀等价的。
回到我们的问题,我们在扔第一个鸡蛋的时候,假如我们选择了第N层作为第一次扔的层数,则有两个可能:
N >= k: 鸡蛋1碎,鸡蛋2可以线性查找1...N-1层,一共需要1+N-1=N次。
N<k: 鸡蛋2没有碎,我们在N+1...100层中解决同一个问题,但是扔的次数少了1.
按照最大熵原理,因为我们不知道任何事先的信息,这两种选择的概率都是等价的,我们要求得最优,就只能让它俩带来的代价一致,也即我们应当选择N,使得无论那种情形发生,我们最终的尝试次数都是一致的。
对于N >= k的情况,一共需要N次,所以对于N<k的情况一共也必须是N次才成。则我们在N+1...100中解决问题,所尝试的次数应当为N-1,此时我们已经成功排除了N层.
可以观察到类似的决策中,从第一次到第N次,我们依次排除了N, N-1, ...1层。
所以我们有
N+N-1+...+1 = 100,或者
N(N+1)/2 =100
容易求得N=14
就是按照这样一个平凡的基本原理,我们求出了这个问题的最优解。实际上,从最大熵原理出发,可以推出近现代信息学上一堆著名的公式和方法,比如大名鼎鼎的卡尔曼滤波器,比如人工智能中的语义分析。或许,越是简单自然的东西,越能反映出这个世界终极的秘密吧。
备注:
这道问题是一个朋友出给我的,我想了大约一分钟,就想透了其中的关键。问题本身并不难,但其解决思路却蕴含了一个基本的原理——最大熵。这或多或少让我感到意外和惊喜。
扩展思考,
一般的,如果我们手头有m个鸡蛋,去尝试n层楼,需要试多少次?
Monday, October 31, 2011
从二到三
“道生一,一生二,二生三,三生万物”
——《道德经》
初读这句话的人,可能觉得这就是句颇为罗嗦的大白话,也有人会说这就是归纳法的基本思想。
从一到二,再从二到三,是否是代表了相同的含义呢?为何是“三生万物”,而不是一或二生万物呢?
今天,我们就来谈谈二和三这两个神奇的数字。
二——完备的最小集
在东方的哲学里,从一开始,二就有着无可替代的神奇含义。任何事物都是存在着对立面,即万物为阴阳,阴阳相生相克,才有了世界的运行。如果只有一,那么孤阳不生,独阴不存,世界这个大系统也就不能成为循环演变的系统,而只是单一的元素了。从这个意义上,二乃是系统的最小集。
现代的计算机科学有二进制,简简单单的0和1构造起了无穷复杂可能的虚拟系统。有人说之所以不选其他进制乃是为了方便制造的实现,这有道理,但并不全对。实际上,从信息论的角度来看,给定固定长的空间,若想表达尽可能多的信息,是存在最有解的。
例如,给N位状态,选择X进制,使得X^(N/X)尽可能的大,采用微积分运算容易求得X=e。使得,并非是巧合,最大的信息密度出现在我们选择自然对数作为进制的时候。但是由于自然对数自身为无理数,所以我们只能选择2进制或者3进制。
实际上,可以证明,3进制的表达效率是要优于2进制的。但是考虑到2进制的表达效率其实不差,再加上系统实现的代价,我们还是选择了2进制。
当然,当年发明计算机的时候是否考虑过表达效率,我无法获知。
三——变化的开始
我们生活的空间是三维的,因此,对于人类来说,考虑超过3维的问题往往就意味着复杂度的爆炸。
有一个有趣的问题,一个酒鬼喝醉了酒,随机的晃荡,问他能否晃荡到家。假设随机往各个方向的概率相等。
这个问题的答案相信很多人都不那么容易猜到:当酒鬼游荡的空间是1维或者2维的时候,他晃荡回家的概率是无限大,即他总能瞎猫碰到死耗子;但是一旦达到3维或以上,回家的概率将变成无限小,即宇宙毁灭也回不了家。
从二到三,简单的量变引发了根本的质变,很神奇,对不对?
只有二态的系统往往是简单的,线性的,而一旦引入另外的维度,系统的复杂性就瞬间增加,变得复杂,非线性。
计算机中著名的set问题,当是2-set时,该问题为P问题;当为3-set时,则跳跃为NP问题。类似的例子,举不胜数。
三是复杂的开始,是变化的开始。但若是继续引入更多的维度,系统的复杂和非线性度进一步增加,则系统将可能极度不稳定,也难以构造稳定的存在。
所以,或许人类该万分的庆幸,我们的世界,刚刚好。
反过来再看“三生万物”,冥冥中,我们已无法再多感慨古人的智慧和直觉。
——《道德经》
初读这句话的人,可能觉得这就是句颇为罗嗦的大白话,也有人会说这就是归纳法的基本思想。
从一到二,再从二到三,是否是代表了相同的含义呢?为何是“三生万物”,而不是一或二生万物呢?
今天,我们就来谈谈二和三这两个神奇的数字。
二——完备的最小集
在东方的哲学里,从一开始,二就有着无可替代的神奇含义。任何事物都是存在着对立面,即万物为阴阳,阴阳相生相克,才有了世界的运行。如果只有一,那么孤阳不生,独阴不存,世界这个大系统也就不能成为循环演变的系统,而只是单一的元素了。从这个意义上,二乃是系统的最小集。
现代的计算机科学有二进制,简简单单的0和1构造起了无穷复杂可能的虚拟系统。有人说之所以不选其他进制乃是为了方便制造的实现,这有道理,但并不全对。实际上,从信息论的角度来看,给定固定长的空间,若想表达尽可能多的信息,是存在最有解的。
例如,给N位状态,选择X进制,使得X^(N/X)尽可能的大,采用微积分运算容易求得X=e。使得,并非是巧合,最大的信息密度出现在我们选择自然对数作为进制的时候。但是由于自然对数自身为无理数,所以我们只能选择2进制或者3进制。
实际上,可以证明,3进制的表达效率是要优于2进制的。但是考虑到2进制的表达效率其实不差,再加上系统实现的代价,我们还是选择了2进制。
当然,当年发明计算机的时候是否考虑过表达效率,我无法获知。
三——变化的开始
我们生活的空间是三维的,因此,对于人类来说,考虑超过3维的问题往往就意味着复杂度的爆炸。
有一个有趣的问题,一个酒鬼喝醉了酒,随机的晃荡,问他能否晃荡到家。假设随机往各个方向的概率相等。
这个问题的答案相信很多人都不那么容易猜到:当酒鬼游荡的空间是1维或者2维的时候,他晃荡回家的概率是无限大,即他总能瞎猫碰到死耗子;但是一旦达到3维或以上,回家的概率将变成无限小,即宇宙毁灭也回不了家。
从二到三,简单的量变引发了根本的质变,很神奇,对不对?
只有二态的系统往往是简单的,线性的,而一旦引入另外的维度,系统的复杂性就瞬间增加,变得复杂,非线性。
计算机中著名的set问题,当是2-set时,该问题为P问题;当为3-set时,则跳跃为NP问题。类似的例子,举不胜数。
三是复杂的开始,是变化的开始。但若是继续引入更多的维度,系统的复杂和非线性度进一步增加,则系统将可能极度不稳定,也难以构造稳定的存在。
所以,或许人类该万分的庆幸,我们的世界,刚刚好。
反过来再看“三生万物”,冥冥中,我们已无法再多感慨古人的智慧和直觉。
Wednesday, September 07, 2011
VXLAN
近期,业界大鳄Cisco联合VMWare、Broadcom等提交了名为VXLAN的RFC draft。链接在此。该标准是Cisco阵营暧昧许久以来,第一次对面向新一代数据中心特殊环境的网络架构核心解决方案。
一时间,引发了业界和学术界对这一敏感话题的关注。
那么,首先VXLAN是要解决什么问题?
简单的说,就是L2 over L3,或者说,在传统的IP层上虚拟出一个lan环境。
这一技术的典型应用就是新一代的数据中心。我在《拨云探月——云计算话题浅析》一文中曾提到过。物理的L2连接,具有简单、敏捷等优势,但难以适用到大规模网络。而在数据中心的环境中,恰恰需要有一套简单而大规模的网络连接。于是,在L3之上虚拟L2就成为了很自然的策略。使用L3来解决规模带来的代价,实现跨多个物理子网,利用虚拟的L2提供简单方便的网络部署和业务实现。
要实现这一策略,有不同的手段。在包头上做文章,实现管道是Cisco等老牌设备商最擅长也是最喜欢的手段之一。VXLAN的实现,也是这一技术的体现。通过添加一个8个字节的VXLAN包头,网包携带了8位的标识和24位的vlan id信息。因此,理论上将支持达到16M的不同虚拟子网。
Cisco宣称将在2011年9月份试图在其数据中心的大杀器——nexus 1000中尝试支持(beta)。这样做的优势是显然的,即
Cisco的老用户们只需要继续花钱购买Cisco的新产品,即可解决问题。另一方面,且不谈使用不断的添加包头的手段来解决一个个新的问题,思路是否正确,问题自然也是显著的。
1 新用户必须要让自己绑定到Cisco的漏水严重的大船上,而且很可能不能兼容其他家的产品。
2 使用额外的包头携带信息,会造成额外的传输代价
3 16M的限制,目前虽然够用,但是不scalable,未来的事情谁也不好说。
4 贵。
实际上,真正用户的需求还应该有下面几个方面。
1 开放。不仅要某家能做,其他家也可以做,而且还可以支持多家一起混合。
2 可扩展。
3 便宜。
从我的角度,要实现满足上述需求的L3 over L2解决方案,并非是个太难的问题。学术界已经有了很多有益的尝试和成果。甚至有些成果也已经开始逐渐变成产品,包括风头甚盛的infinetics和一些更开放更具有性价比的方案。
当然,根本上还是屁股决定脑袋,站在传统龙头设备制造商的角度,自然恨不得所有问题都自家一个设备解决了,哪怕解决的ugly点,解决的昂贵点,因为都是客户在买单。
但在IT领域,任何一家企业,到了技术不占主导的时候,也往往就是开始走下坡路的时候。
一时间,引发了业界和学术界对这一敏感话题的关注。
那么,首先VXLAN是要解决什么问题?
简单的说,就是L2 over L3,或者说,在传统的IP层上虚拟出一个lan环境。
这一技术的典型应用就是新一代的数据中心。我在《拨云探月——云计算话题浅析》一文中曾提到过。物理的L2连接,具有简单、敏捷等优势,但难以适用到大规模网络。而在数据中心的环境中,恰恰需要有一套简单而大规模的网络连接。于是,在L3之上虚拟L2就成为了很自然的策略。使用L3来解决规模带来的代价,实现跨多个物理子网,利用虚拟的L2提供简单方便的网络部署和业务实现。
要实现这一策略,有不同的手段。在包头上做文章,实现管道是Cisco等老牌设备商最擅长也是最喜欢的手段之一。VXLAN的实现,也是这一技术的体现。通过添加一个8个字节的VXLAN包头,网包携带了8位的标识和24位的vlan id信息。因此,理论上将支持达到16M的不同虚拟子网。
Cisco宣称将在2011年9月份试图在其数据中心的大杀器——nexus 1000中尝试支持(beta)。这样做的优势是显然的,即
Cisco的老用户们只需要继续花钱购买Cisco的新产品,即可解决问题。另一方面,且不谈使用不断的添加包头的手段来解决一个个新的问题,思路是否正确,问题自然也是显著的。
1 新用户必须要让自己绑定到Cisco的漏水严重的大船上,而且很可能不能兼容其他家的产品。
2 使用额外的包头携带信息,会造成额外的传输代价
3 16M的限制,目前虽然够用,但是不scalable,未来的事情谁也不好说。
4 贵。
实际上,真正用户的需求还应该有下面几个方面。
1 开放。不仅要某家能做,其他家也可以做,而且还可以支持多家一起混合。
2 可扩展。
3 便宜。
从我的角度,要实现满足上述需求的L3 over L2解决方案,并非是个太难的问题。学术界已经有了很多有益的尝试和成果。甚至有些成果也已经开始逐渐变成产品,包括风头甚盛的infinetics和一些更开放更具有性价比的方案。
当然,根本上还是屁股决定脑袋,站在传统龙头设备制造商的角度,自然恨不得所有问题都自家一个设备解决了,哪怕解决的ugly点,解决的昂贵点,因为都是客户在买单。
但在IT领域,任何一家企业,到了技术不占主导的时候,也往往就是开始走下坡路的时候。
Thursday, August 11, 2011
理工科phd必备高效工具
updated: 2013/10/12
理工科的phd们多不容易,除了要搞项目,还得攒论文。因此,高效率的工作模式无疑十分重要。
以下筛选了个人在使用过程中感觉能明显提高效率的工具,遵循“少而精”的原则,多数支持通用平台(win, linux, mac, etc.),希望后入门的phd们可以藉此做更高效的科研。部分工具对于研发人员也很有用。
数学计算
笔记整理
论文管理
参考文献
书籍管理
文本编辑
编程实验
注重运行效率:C, C++或Java
版本管理
集中式:SVN
数据同步
图表相关
数据可视化
比较全面的可视化:Gephi
图形自动生成:Nodebox
论文写作
LaTeX
报告演讲
latex beamer包
ppt、keynote相关软件
欢迎建议,持续更新ing...
Tuesday, August 09, 2011
网络流管理与交通流管理
曾经有幸听过一个交通流管理方向的专家做过一个研究报告。提到他们的研究成果被美国政府采用后,提高了接近十个百分点的性能(具体啥性能指标已经忘记了)。那时我刚接触网络流量管理这个课题不久,还只有个大概的认识。但即使如此,那个讲座还是引发了我不少的思考。
网络流管理跟交通流管理,貌似风马牛不相及的两个课题,其实有着惊人的内在关联。
从目的上看,两者都是为了提高系统的某种性能,包括容量、鲁棒性等,同时要尽量减少突发情况带来的损失,尤其典型的场景是拥塞避免。对网络来说,拥塞意味着大量的数据包挤占了有限的带宽,造成数据丢失(目的不可达);对于交通来说,则是为了减少堵车发生,也是为了保障可达性。但是两者在可控手段上和物理过程上的差异,造成了在实际应用中的天壤之别。
网络上的流量管理,特别是现代的互联网,已经被研究了二十多年,但一直到今天都没有有效的手段去达到让人满意的控制。而交通流管理,已经有太多行之有效的思路和手段。我曾总结说,现在的交通网在讨论解决的类似问题,至少十年前互联网的专家们就已经研究过了(所以搞交通网络的专家们翻翻互联网上的相关问题的研究论文,未必不是一个好思路)。
抽象的看,一个系统,要避免拥塞,要么从提高容量角度入手,要么从降低压力峰值入手。提高容量,对于交通网络来说意味着增加更多的车道,对通信网络则意味着升级设备。无论对交通网络还是通信网络,这都不是能即时有效的手段。因此,两者都想到了如何去降低压力峰值,或者说如何做好调度优化。恰恰在这一点上,交通网络上的控制显示出了巨大的可操作性。
相比较互联网中以接近光速穿行的信号来说,交通网络中的承载单元——典型的如汽车,不仅速度慢,而且随时随地可以停住。将载荷停住对通信网来说则意味着存储。无论是技术的限制还是机制的设计约束,随时随地的高性能存储对于现代的通信网络来说都是“不可能的任务”。因此在流量调度上通信网络的要求要高的多,也难得多。同时也因为互联网是多个自治系统的自由连接,在交换节点上大规模的部署新的调度技术更是难上加难。
那么,通信网上的流量管理就没有一点优势了么?
当然也不是。相比较交通网来说,通信网上的流量管理也存在显著的优势。一是对载荷的可控性。载荷在经过每个节点时都存在被任意处理的潜能;二是允许丢弃重传;三是可控。每个载荷都严格遵守“交通规则”。也正是从这几点出发,以MPLS为代表的相关技术成为了ISP网络中事实上的标准。
写到这里,突然想到除了交通网和通信网之外的另一张大网——电网,也存在类似的问题。电网的调度跟互联网类似,也不存在任意灵活的存储(目前的电力存储,还有太多问题,最显著的就是容量和吞吐率,其次是效率)。另一方面电网又没有通信网络可以任意丢弃重传的灵活性。因此,电力网络的调度将更加困难,也是下一步马上面临的更大的挑战。美国前几年的电力网故障造成大面积停电,中国西部大开发早了很多发电基地,却无法输送出来。这都是一些经典的例子。当然,凡事有利有弊,电网调度也存在它有优势的一点。因为电力是能源,其应用十分广泛,既然现在输送不出来,为何不能本地消化掉?例如东部的生产基地如果直接建造到西部去,即消耗了西部的富余电力,又降低了东部的用电压力,可谓一举两得。
Saturday, June 11, 2011
随机——概率幽灵
有一个程序员都看的懂的网络流行笑话,说有人写了一个超快的随机数生成函数,全部代码如下:
int getRandomNumber(){
return 4;
}
相信不少人看了都会会心一笑,说这程序员也太懒了,一直返回4,怎么就能生成随机数了呢?可是等我们仔细想象随机数的定义,随机数应该是跟此前发生的数无关的数,这也就意味着,无论此前生成的是什么数字,都不管,需要重新生成。
那么,每次产生4有什么问题呢??
有数学家宣称,让一只长生的猴子敲击键盘无数次,总有一段是莎士比亚的某一部作品。其实我们可以推广下,让一只长生的猴子敲击键盘无数次,我们总可以找到人类历史上出现过的所有信息。
回到我们的问题,一个随机数生成器,某天生成的序列是“444444444……”,并非毫无可能,按照概率论的说法,随机数生成器生成的序列中,总会有任意一个数字的无限长的重复子序列。
也许有人已经开始迷糊了:“等一下,你怎么能说一直是某个数字的重复序列是随机序列呢,虽然你说的似乎有道理……”
让我们再来看一个简单的例子。
给你一枚普通的硬币,抛起来,掉到地上,假设硬币不能立起来,那么你猜正面的可能性有多大?
“这还用问,小孩子都知道,是1/2。”
好的,我们抛一下,结果是正面,那么我再抛一下,结果还是正面的概率是多少呢?
“嗯,应该也是1/2吧”
好的,我们再抛一下,结果还是正面,那么再抛一下呢?如果我连续抛出来了10个正面之后,下一次我再抛出正面的概率是多大呢?
可能有人额头已经开始出汗了,掏出笔,想一想概率论上学到的道理:每次抛都是独立事件,互相应该不受干扰,那么下一次结果是正面的概率应该仍是1/2。但是连续抛出11次正面,天哪,这个概率太小了。。。。似乎下一次更有可能出现反面啊。。。
好吧,相信到这里,大部分人已经彻底晕了。如果你还没晕,相信我,要么是你概率论没学好,要么是……你的神经无比粗壮。
这几个例子说明的其实都是随机。
现代概率论可以告诉我们某某事情发生的概率是多少,但是永远无法准确的告诉我们发生与否。事实上,概率为1的事情不一定会发生,而概率为0的事情也有可能会发生。
是不是听起来挺可怕?就像一个数学幽灵一样,无法捉摸。
实际上,当我们再仔细思考概率论的基础时,会发现数学上的假设与真实之间,出现了那么一丝的不和谐。什么叫相互独立事件?之前抛硬币跟下次抛硬币之间的独立真的符合数学上的理想定义么?
问题到了这一步,是现代最伟大的数学家或物理学家都无法回答的了。因为这涉及到这个宇宙的基本性质。在时空上看,多个事件点之间的联系并不是那么好理解。
一种最粗鲁的解释是我们的宇宙在时空中是不断分裂的,任何事件的发生的多个可能结果都导致了一个新的宇宙,我们在这个宇宙中只是一种偶然。因此,我们未来要做什么其实跟过去无关,因为总会导致均等机会的新的宇宙产生。
另一种解释,是宇宙中有某种神秘的力量,让整体稳定分布符合概率统计,小概率事件的发生,其实类似池塘水波的震荡,有波峰,就有波谷,而且当没有外在力量影响的时候,产生大水波的可能性很小,但允许极小概率的局部小震荡。这样的话,某天我们发现一件不可思议的小概率事件发生的时候,其实是发生了震荡的缘故。
以上两种解释似乎都有一定道理,但可能只有后人才有可能更完善的理解这个问题了。
int getRandomNumber(){
return 4;
}
相信不少人看了都会会心一笑,说这程序员也太懒了,一直返回4,怎么就能生成随机数了呢?可是等我们仔细想象随机数的定义,随机数应该是跟此前发生的数无关的数,这也就意味着,无论此前生成的是什么数字,都不管,需要重新生成。
那么,每次产生4有什么问题呢??
有数学家宣称,让一只长生的猴子敲击键盘无数次,总有一段是莎士比亚的某一部作品。其实我们可以推广下,让一只长生的猴子敲击键盘无数次,我们总可以找到人类历史上出现过的所有信息。
回到我们的问题,一个随机数生成器,某天生成的序列是“444444444……”,并非毫无可能,按照概率论的说法,随机数生成器生成的序列中,总会有任意一个数字的无限长的重复子序列。
也许有人已经开始迷糊了:“等一下,你怎么能说一直是某个数字的重复序列是随机序列呢,虽然你说的似乎有道理……”
让我们再来看一个简单的例子。
给你一枚普通的硬币,抛起来,掉到地上,假设硬币不能立起来,那么你猜正面的可能性有多大?
“这还用问,小孩子都知道,是1/2。”
好的,我们抛一下,结果是正面,那么我再抛一下,结果还是正面的概率是多少呢?
“嗯,应该也是1/2吧”
好的,我们再抛一下,结果还是正面,那么再抛一下呢?如果我连续抛出来了10个正面之后,下一次我再抛出正面的概率是多大呢?
可能有人额头已经开始出汗了,掏出笔,想一想概率论上学到的道理:每次抛都是独立事件,互相应该不受干扰,那么下一次结果是正面的概率应该仍是1/2。但是连续抛出11次正面,天哪,这个概率太小了。。。。似乎下一次更有可能出现反面啊。。。
好吧,相信到这里,大部分人已经彻底晕了。如果你还没晕,相信我,要么是你概率论没学好,要么是……你的神经无比粗壮。
这几个例子说明的其实都是随机。
现代概率论可以告诉我们某某事情发生的概率是多少,但是永远无法准确的告诉我们发生与否。事实上,概率为1的事情不一定会发生,而概率为0的事情也有可能会发生。
是不是听起来挺可怕?就像一个数学幽灵一样,无法捉摸。
实际上,当我们再仔细思考概率论的基础时,会发现数学上的假设与真实之间,出现了那么一丝的不和谐。什么叫相互独立事件?之前抛硬币跟下次抛硬币之间的独立真的符合数学上的理想定义么?
问题到了这一步,是现代最伟大的数学家或物理学家都无法回答的了。因为这涉及到这个宇宙的基本性质。在时空上看,多个事件点之间的联系并不是那么好理解。
一种最粗鲁的解释是我们的宇宙在时空中是不断分裂的,任何事件的发生的多个可能结果都导致了一个新的宇宙,我们在这个宇宙中只是一种偶然。因此,我们未来要做什么其实跟过去无关,因为总会导致均等机会的新的宇宙产生。
另一种解释,是宇宙中有某种神秘的力量,让整体稳定分布符合概率统计,小概率事件的发生,其实类似池塘水波的震荡,有波峰,就有波谷,而且当没有外在力量影响的时候,产生大水波的可能性很小,但允许极小概率的局部小震荡。这样的话,某天我们发现一件不可思议的小概率事件发生的时候,其实是发生了震荡的缘故。
以上两种解释似乎都有一定道理,但可能只有后人才有可能更完善的理解这个问题了。
Sunday, May 29, 2011
世界计算机名校的网络课程
虽然排名方法有很多种,但公认的计算机领域的世界顶级名校至少包括MIT、Stanford、UCB和CMU(排名不分先后)。这四所高校在计算机领域无不处在领头地位,在专业上又各有偏重,一起构成了计算机学术界的半壁江山。
下面是我选出的这四所高校在网络方面的代表课或特色课,授课者都是计算机界的大牛,面向对象均为研究生。
MIT
课程网址:http://mit.edu/6.829
主要开课人:Hari Balakrishnan
面向对象:研究生
内容:大规模网络系统的设计、实现、分析、测试等
形式:阅读(论文、技术报告、RFC)+报告
Stanford
主要开课人:Nick McKeown
面向对象:研究生
内容:网络系统设计、分析、下一代网络等
形式:阅读(论文为主)+实践(基于Openflow)
UCB
主要开课人:Ion Stoica, Scott Shenker
面向对象:研究生
内容:网络各层研究、网络热点问题等
形式:阅读(论文为主)+讲座+专题研讨
CMU
主要开课人:Srinivasan Seshan
面向对象:研究生
内容:网络原理、设计原则、应用问题等
形式:阅读(论文为主)+讲座+讨论
Friday, May 20, 2011
“拨云探月”——云计算话题浅析(二)
在上篇文章中,我们分析了云计算出现的原因和必然性,相信可以帮助大家更好的理解和把握云计算的定位。在本次IT的泡沫即将破灭之际,必然要有大批没有质量的企业和产业被淘汰掉,遴选的唯一原则还是我们根本所说的“生产力原则”。因此,真正掌握云计算核心技术的企业是肯定可以存活下来的,也只有这批新型的企业模式,才会让IT产业更加蓬勃和高效。本篇文章中我们将探讨涉及到云计算/数据中心的几个核心技术问题,并展望下云计算的未来发展。
虚拟化
虚拟化的概念从有了计算机,甚至在计算机发明之前就已经被广泛的应用。但从来没有过一个时代像云计算时代一样,使得虚拟化变得如此重要。要理解虚拟化对云计算为何如此重要,首先就要深刻把握虚拟化的内涵。什么是虚拟化?表面看来似乎很容易理解,但要下个准确的定义却不是那么简单。网上随便一搜,说法众说纷纭。Wikipedia上说虚拟化是“一個表現邏輯群組或電腦資源的子集的進程”,百度百科上说“虚拟化是指计算机元件在虚拟的基础上而不是真实的基础上运行。”大大小小的技术论坛上也是瞄准添加一层新的抽象层的角度来进行描述,简而言之就是重新抽象。
应该说这些说法都多多少少的描述了虚拟化要做的事情或者相关的技术手段,但并没有涉及到虚拟化的本质所在。以最常见的主机虚拟化为例,一台硬件机器放在那里,怎么让它能跑多个程序甚至是多个操作系统?很自然的我们采取的手段是创建一个新的虚拟层,在此新层上运行多个程序/系统,并让它们感觉不到其他个体的存在。这个过程就典型采用了虚拟化的手段,但我们不能把这个手段就当做虚拟化。
我曾思考这个问题数年,却一直无法用语言具体描述那种玄妙的体会,直到有一天看到下面的文字,突然如醍醐灌顶。
“道可道,非常道。
名可名,非常名。
无,名天地之始,有,名万物之母。”
这是《道德经》第一章一开头的文字,相信不少人如我都曾读过,却从来没把它跟云计算联系起来。这一段说了两件事情,第一件事情是“道”,这是根本,是宇宙产生的本源依赖;第二件事情是“名”,是万物变化的初始动力。
何为“名”?
为何一棵树要被定义为一棵树?
为何一块石头要被定义为一块石头?
在为万物起名之前,万物早已存在;为万物起名之后,万物并没有变化。变化的是我们,是命名者。就如同硬件的机器一样,造好后摆放在那里,你让它被解释为一台机器,那么就可以做一台机器做的事情;你让它被解释为多台机器(对程序或系统而言),那么它就能同时运行多个实例。
“名”,或者说解释,才是虚拟化的本质所在。
从这个角度,我们重新来看待虚拟化和云计算的关系。在上一篇中提到,现代可扩展的数据中心主要通过糅合大量不可靠的廉价节点来构造一朵具备强大计算能力并可靠的云。从本质上说正是一个“名”的问题,或者说虚拟化的问题。我们要把普普通通的不同类型的硬件机器解释为统一的数据中心!
因此,这里面就涉及到大量的虚拟化相关的技术问题。包括性能、扩展、管理、可靠性。值得庆幸的是,虚拟化技术这些年来一直在飞速发展(大量的软件虚拟化要容易的多),并未对云计算的需求形成显著瓶颈。
交换
虚拟化虽是云计算发展的基础技术,但因为应用场景十分类似,并未形成瓶颈。而另外一项根本技术——交换则不然。我们知道,现代的Internet实际上是运行在以太网及少量其他类型网络基础上的。别看Internet规模庞大,构造的原理却十分简单——利用交换节点把主机连接起来。
一般来说,我们可以很轻松的通过二层交换机连接本地网络,然后多个交换机再互联形成一个不小的局域网,利用二层交换机构建的局域网可以运行的十分稳定,似乎是个不错的解决方案。但当要扩展出去的时候,就有了新的问题。
我们知道,交换机之所以能实现交换,是因为它记住了每个端口上的机器mac,或者说它知道谁在哪里。而主机位置可能会发变化,例如从一个端口变到另一个端口,这个时候交换机就需要有机制来不断的更新它的内部记录,以随时跟踪最新的机器位置信息。当需要完成交换的主机数目增多的时候,不仅硬件上的端口不够用,内部的位置信息维护也成了大问题。不光维护大量的位置数据无法实现快速的查找。当机器位置更新频繁的时候,大量的arp相关报文将使交换机疲于应付。
为了解决这个问题,人们在二层以上新定义了IP层,试图利用IP地址的聚合来降低这些代价(当然,IP层的意义远不仅于此)。这也就是路由的由来。传统的交换机无法完成三层的交换(现代交换机很多都支持三层交换,但都是小规模),而路由器则可以通过维护庞大的IP段表来实现不同本地网络之间的流量传输。但相比交换机而言,路由器无法很快的更新位置信息。一次路由错误可能会导致网络几分钟甚至到几个小时无法work。
总结一下,二层交换能较快的跟踪位置信息,但无法处理大规模网络;三层的路由则相反。
对于目前的互联网来说,二层和三层交换的紧密配合,能够很好的处理目前的情况。毕竟,我们从一个地区转移到另一个地区,总是默认要重新连接,并不需要保持工作的连续。而到了现代的数据中心,问题便浮现出来了。
由于我们有大量的互联网的设计经验,很自然的,在设计现代数据中心的时候借鉴了类似的结构。这使得现代的数据中心从某种意义上来说其实是一个小型的Internet,只是真正的Internet并不属于某一家企业来统一管理而已。从Internet到数据中心,计算的个体从个人主机变成了虚拟机,同时由于业务连续的需要,移动性的需求变得敏感起来。即在虚拟机的迁移过程中,我们希望能保持它提供服务的连续。在二层网络中这不是问题,二层交换机能很好的跟踪位置信息,但是到了大规模的数据中心,我们不得不采用类似三层交换的机制,这就使得位置的跟踪与规模的扩展之间的矛盾凸现出来。
所有炒数据中心的交换设备,都躲不开这个问题。这一问题在传统的交换架构下其实并没有太好的解决思路,所以必须要改革。学术界以VL2为代表的一系列解决方案,都是试图将位置信息与名称信息(IP信息等)剥离开来,绕过矛盾。
其实,位置与名称信息的剥离,在数年前研究Internet的时候就提过相关思想,但因为应用并不多见不为人所关注,但到了数据中心就成了首要解决的问题。
另外一个问题,也是传统交换机制在新挑战下被发现的,即多路径的问题。简而言之,传统的交换机架构是不允许成环的,通用的生成树协议会自动维护唯一的两点之间的路径。带来的好处是可以避免复杂的交换管理,问题是浪费了可能存在的路径。
在互联网时代,我们可以容忍点到点吞吐量不满载,可以通过冗余链路来实现高可靠的冗余。但到了数据中心时代,首要的需求是交换性能,为了实现性能和可靠性,我们恨不得充分利用每一条链路。这种情况下,就不得不舍弃生成树,重新设计更为复杂的交换机制。这一问题也给现代交换设备生产商带来了新的挑战。
无论是Cisco的Nexus/FabricPath Jawbreaker,还是Juniper的QFabric,都为了数据中心带来了新的技术思想和解决方案,但都有其存在的问题。目前产业界,还远没有一种完善的方案能力压群雄,成为事实的标准。这也使数据中心这块大蛋糕之争,充满了不确定的迷雾。
其他问题
其实,由于现代数据中心结构与Internet的相似性,原先很多的问题,在数据中心的应用环境中仍然存在。例如安全问题、能耗问题、灾备恢复等。因为数据中心的管理单一化、结构化,安全问题主要面临是外部的攻击和内部的数据管理。虽然看似简单的,但安全性的需求更高了,因为一旦出现问题,带来的损失将是惊人的。亚马逊因为一个小的配置错误导致部分机器宕机就是一个鲜活的例子。
能耗问题这些年颇为火,除了环保主义者的吹捧外,也是实实在在的利益相关。几十万台机器和交换设备每天烧掉的电费也是个惊人的数字。因此,如何实现绿色型数据中心是实在之谈,而非哗众取宠。以谷歌、Facebook等IT巨头的设计为例,主要采取的方法包括动态调整负载以关闭部分节点,减少冷却成本、采用低耗硬件等思路。
灾备恢复始终是系统设计的重要指标。网络结构的复杂化,使得配置和管理成为不可能的任务。而在数据中心中,由于拓扑固定、管理同质,使得管理任务大为简化。但人始终不能胜任对故障的及时处理。一旦出现故障,如何及时的甚至零损失的恢复,现代数据中心并没有很好的解决思路,这将依赖于网络管理技术和设计上的进一步发展。
发展趋势
从目前的情况来看,数据中心的发展是必然,同时,由于技术的发展,未来的数据中心预计将出现如下几个趋势。规模进一步增大。现在的数据中心往往有几十万节点的规模,但在未来这一规模将更加庞大。但规模的增加不意味着体积等的增加,不意味着数据中心数量的增加。
能效进一步提高。无论是从硬件的发展还是架构的设计上,能效都将成为重中之重。
管理进一步简单。交换技术的发展将提出新型的数据中心交换设备,使得交换节点在整个数据中心中的比例下降,同时,交换设备的智能化得到提高,少数管理员将能轻松管理大规模的数据中心。
性能必然提高。无论是数据中心群的被提出,还是根本技术的改变,例如采用光数据中心,新的存储方式等,都会使得数据中心的性能得到进一步提高。甚至在不远的未来,可能云计算真的就变成了“智”计算——由远在云端演变成时时刻刻、随时随地,由用户可感知演变成融入生活、无处不在。
Friday, May 13, 2011
Interop 2011 Las Vegas 大会
注:2011年5月11日下午,Las Vegas McCarran国际机场候机厅,于老虎机闹腾的音乐声中。
作为IT领域一个比较年轻的会议,Interop的定位却不低,官网自己宣传的定位是“Interop is the leading business technology event with the most comprehensive IT conference and expo available”。跟其他大会类似,分为专题会议和大型会展(Expo)。一般来说,从参与会展的生产商list基本上就能确定大会的影响力。从这个角度,Interop确实称得上是全球IT领域颇具影响力的大会了,基本上叫得出名和叫不出名的IT厂商都有出席。
自06年举行以来,每年至少分别在春季和秋季在Las Vegas和New York举行一次,今年更是夸张,增加了日本的Tokyo和印度的Mumbai,全球范围内要举行4次(喜欢旅游的同学们可不要错过)。Las Vegas这次是今年首次,规模十分惊人,数百家企业参加Expo,专题会议也有近百个,会期从5月8日到12日持续5天,题目更是几乎覆盖了IT技术的所有领域。
从个人参会体验看,云计算/数据中心确实是如日中天,几乎每家都跟这个靠近乎,Expo上更划出了专门的一块作为云计算区(另一块专区是老问题——安全)。不管是业界巨擘如Cisco、Juniper、HP等等,还是一些Startup类公司。讨论的热点也多在数据中心的交换、虚拟化、管理等关键话题上。值得一提的是,NEC、HP、Juniper、IBM等几家都参与进了Openflow Lab,在会上由Big Switch牵头做了展示,关注的人不少,不过感觉好奇的多,懂技术的少(Big Switch这个startup很有意思,有机会单独撰文予以介绍)。
另外,跟前些年参会大家都是人手一台thinkpad不同,今年不少人是一台ipad(当然做技术的还是thinkpad居多,像我过来前犹豫很久还是带着小黑过来了),会展的商家吸引人的花样也多是ipad。我老早就说过,单纯从革命性上来说,iphone远不及ipad,这是真正是找对了需求。商旅人士要求的无非一个是待机长、一个是轻便和随开随用,这点上传统的laptop或cellphone都很难搞定。
最后8g下做key note的几个高管,秃顶的不少呀,至少是前秃,级别高的甚至顶秃,看来确实是要“聪明绝顶”才能做高管了。
其他闲话不再多说,上pic(主要是5月10日拍的)。

keynote现场。


Juniper在会上炒作QFabric,但就在当天得知,设计人David Yen跑到Cisco整Nexus去了,Cisco估计乐坏了。

MS这些年露面不少,甚至网络会议也纷纷掺和。

云计算专区,IBM、EMC、Intel、MS等都在这个区。

不知道为何,就是喜欢EMC的这种蓝色style,多来一张。

EMC俨然虚拟化的领头人,碰上云计算这个千载难逢的好机会更是出尽了风头呀。


混久了圈子的人,看口号基本就能猜出是哪家公司。IBM这些年无论在啥场合都炒创新和智能。虽然这个理念大家都会用,但被IBM用出来就气象俨然,俨然宗师气派。



Juniper的QFabric,简单的说就是一块超大的交换机。我原来讨论数据中心问题的时候曾跟导师开玩笑,说随着技术发展,将来能实现N对N的超级大交换机,能力无限,那么数据中心很多问题都迎刃而解了。本是一句玩笑话,谁知1个月后,就获知了QFabric推出的消息。

HP带来了自家的一体化的交换、安全、存储解决方案。

of lab名头颇大,吸引了不少眼球,但炒作的还是基本的of理念。


of lab演示现场。



跟Cvm的工程师聊,说隔了两年时间才由16core升级到32core,对于IT产业来说,感觉产品的市场周期有些略长了。不过人家的东西还是蛮好用的。


安全专区,老面孔颇多,新面孔也不少。没有看到Plato,不能再听nir同学侃侃神谈,颇为可惜。




冰雕是吸引观者的老把戏了,不过还是得承认,视觉效果颇佳。


参会的国内厂商,除了华赛勉强算上,就是nsfocus(绿盟)了,听说今年在北美有office了。无论如何,走出国门都颇为不易,希望民族企业们先不要急着内斗,能团结起来,先发展起来成熟的市场其实对大家都有好处,最终走向全球领域的大舞台。
Saturday, April 23, 2011
“拨云探月”——云计算话题浅析(一)
【本文面向读者无需有专业知识。读过本文后可以茶余饭后与人神侃,忽悠“专家学者”问题不大】
时下,云计算是个热门话题,无论学术界、工业界还是商业界,凡是跟云计算扯上点关系的就能吸引人的眼球;反之就觉得“科技”含量不够。无数沾边或者不沾边的企业、专家都纷纷叫嚷云计算,却少见有人静下心来具体分析分析云计算到底是怎么回事。
本文试图通过云计算的起因、关键技术点和未来发展趋势这三个方面对云计算进行浅析,剥去那层“神秘”的面纱。
常识告诉我们,这个世界上没有无缘无故,如果一件事情违背了常理而找不到原因,那么一定是有人在背后捣鬼。
那么云计算的出现究竟是时代发展的自然趋势还是人为的巧合呢?
实际上,计算机的出现也不过几十年而已,在这短暂的几十年里计算模式发生过数次变化。
在巨型机/大型机时代,计算机只能在政府部门或者企业等中才能享有的。一方面造价昂贵、体积巨大、维护成本高,另一方面只有政府部门或者企业等大规模组织才有快速计算的需要。后来虽然有了早期的互联网,但使用计算机仍然是少数人圈子内的权利。这个时代的特色是昂贵集中的计算机+低速的网络+个人用户。
随着技术的成熟和生产工艺的提高,计算机的体积缩小、性能提高、配套的软件系统成熟,微型机(PC)终于慢慢普及开来。个人对于计算机的需求一下子发展起来。很难说是计算机推动了个人生活方式的改变,还是个人生活方式的改变增加了对于计算机的需求。总而言之不光企业,普通生活中也越来越离不开计算机了。这一阶段的计算模型是低速的网络+强大的个人终端。
从巨型机时代到微型机时代的转变有几个关键因素。一是集中式的高性能计算机造价太昂贵,个人用户人手一台不现实。那么能否大家一起share?早期低速几十k的互联网根本无法提供足够的分布能力。这两个关键的因素决定了用户个人终端的出现。可以说,计算由中心转移到终端是用户对于计算的急速增长的需求和脆弱的联网能力之间矛盾无法调和的必然结果。
而到了网络技术成熟的21世纪,解决这一矛盾有了新的可能方案。那就是将计算放到远端(云端),用户减少客户端的成本。这一看似复古的模式实在有着巨大的优势。于是乎,云计算的概念一经提出,就迅速红遍全球,当然这里面也有名字起得好的因素在。
从前面的分析我们可以看出,计算模式的改变并不是某几个人或企业能决定的,根本上说还是技术水平来决定的。是的,一点都不夸张。抽象的看确实就是生产力水平决定了上层的使用模式,即生产关系。
就在写作本文的时候,全球最大的云计算供应商amazon的数据中心出现了严重的故障,造成多家互联网客户服务受到影响,为全球云计算市场增添了一丝阴影。
确然,如果将来大家都绑到云计算上,一旦发生故障将是十分可怕的。这听起来远没有将数据放到自己本地的机器上更为安全。那么为什么云计算的发展还是喷薄如斯呢?
如果从“利”,即经济的角度去看待这一问题,会发现一些有意思的结果。
大家都知道在经济史上,货币的出现是一个经济体系进入较高阶段的重要标志。为什么货币的出现如此重要?其实不在于说减少运输成本啊,市场调控啊等等因素。这些因素也很重要,但是更为关键的在于,货币这一体系极大的解放了生产力!
是的,听起来很夸张,但事实就是如此。在货币作为物品的代替物的时候,在稳定的金融社会,货币自身实际上就代表了生产力的成果。我们运用货币,实际上就是将生产力重新整理,投入新的生产的大循环过程。虽然说,在出现货币之前,我们干的也是这件事情。但这一过程从来没有如此的方便和有效率过。离开了货币,就相当于在生产大循环的某个环节掐住了喉咙。试想,如果一个人要吃饭,就必须自己种地,一个人要吃肉,就必须自己打猎,这一的社会生产力怎么能提高?而方便交换过程的重要手段,就是货币。
更为拔高一些,就是生产关系解放生产力。
对于云计算模式同样是如此,在计算能力被集中管理的情况下,资源可以更为有效的投入到需要的地方去。用户获取计算资源更为便捷和便宜,也更加有效率。因此,云计算的出现,在经济上是一种必然。也因为如此,不同于当年的网站或现在的广告模式,云计算在网络泡沫后必然会存活下来。
当然,更深入一些,在现代金融体制里,形成垄断后的金融大鳄们利用货币的手段可以巧取豪夺,对于未来云计算的发展,是否也会有类似的事情出现呢?
在云计算时代,用户只要通过客户端告诉云端自己的需求,云端完成之后就可以将结果push给用户。这里客户端起到了简单的信息解释的作用,并没有太多技术含量,而真正的快速解决问题需要一个强大的云端。
这个云端就是数据中心。
前面说到云计算模式是看似复古的模式。很重要的一个区别就在于提供计算服务的方式。在巨型机时代一台多用户的巨型机在机房里,各个用户登录上去,自己安排好任务然后让机器执行计算。而在云计算时代,则是几十万台计算机构建的数据中心共同为用户提供服务。而且数据中心内对用户是透明的,用户甚至根本不知道也无需知道自己的任务在哪几台机器上完成。
那么,为什么要用数据中心替代大型机呢?
这个问题在网格计算发展起来的时候曾经有过一个答案——成本。巨型机的成本实在是太高了,以至于只要拿出一部分钱购买大量廉价的PC来搭建网格就能提供接近的计算能力。看起来从成本上考虑,云计算是有太大的优势。但,这并不是最根本的原因,需知为了连接这些PC,数据中心中大量的昂贵的高性能交换机占据了大部分的成本。
那么根本的原因是什么?
说到这里,我们提下著名的摩尔定律。这一定律预测了几十年的芯片产业发展,到了近些年终于不怎么灵了。单块芯片的频率已经接近制造工艺的极限,进一步提高意义不大且成本惊人。Intel等企业早早就看到了这一点,这才提出多核的概念。可以说,多核不仅仅是用户体验改善,根本上是生产工艺局限的必然。看到这里,相信不少人已经明白了。
在信息时代的今天,要成为一朵拥有大量用户的云,所提供的计算资源(和存储资源)是惊人的,这根本不是几台巨型机就能提供的,服务所需要的稳定性也不是巨型机能保障的。没有办法了只好退而求其次,用廉价的机器搭建数据中心。也正是这一模式,成就了Google、Amazon、Facebook等新兴企业。
一个关键的问题是,这一模式是否必然成立呢?
这一问题的核心在于大量低性能节点构建的数据中心能否满足我们的庞大计算需求。
大家都知道蚂蚁搬家,有的蚂蚁搬运树叶,有的蚂蚁搬运粮食,每个蚂蚁搬动的东西有限,大量的蚂蚁一起工作就能产生惊人的搬运能力。这跟云计算的模式十分相似。但是我们知道,蚂蚁搬家再厉害也很难搬动大的石块。为什么?因为石块不能被分解开,成为一只蚂蚁可以搬动的单元。
同样,云计算模式也无法解决“石块”问题。如果一个任务根本无法分解并行进行,云计算的数据中心再庞大也只有仰天长叹了。幸运的是,我们现在碰到的大部分计算问题都可以采用这样或那样的方法来分解,然后并行进行,也正是这一巧合,让云计算在我们的世界上成为了可行。
ps, 本系列的下一篇将侧重分析数据中心中的核心技术和问题,希望关注技术的同仁不要错过。
时下,云计算是个热门话题,无论学术界、工业界还是商业界,凡是跟云计算扯上点关系的就能吸引人的眼球;反之就觉得“科技”含量不够。无数沾边或者不沾边的企业、专家都纷纷叫嚷云计算,却少见有人静下心来具体分析分析云计算到底是怎么回事。
本文试图通过云计算的起因、关键技术点和未来发展趋势这三个方面对云计算进行浅析,剥去那层“神秘”的面纱。
云计算起源
首先为什么会有云计算?常识告诉我们,这个世界上没有无缘无故,如果一件事情违背了常理而找不到原因,那么一定是有人在背后捣鬼。
那么云计算的出现究竟是时代发展的自然趋势还是人为的巧合呢?
实际上,计算机的出现也不过几十年而已,在这短暂的几十年里计算模式发生过数次变化。
在巨型机/大型机时代,计算机只能在政府部门或者企业等中才能享有的。一方面造价昂贵、体积巨大、维护成本高,另一方面只有政府部门或者企业等大规模组织才有快速计算的需要。后来虽然有了早期的互联网,但使用计算机仍然是少数人圈子内的权利。这个时代的特色是昂贵集中的计算机+低速的网络+个人用户。
随着技术的成熟和生产工艺的提高,计算机的体积缩小、性能提高、配套的软件系统成熟,微型机(PC)终于慢慢普及开来。个人对于计算机的需求一下子发展起来。很难说是计算机推动了个人生活方式的改变,还是个人生活方式的改变增加了对于计算机的需求。总而言之不光企业,普通生活中也越来越离不开计算机了。这一阶段的计算模型是低速的网络+强大的个人终端。
从巨型机时代到微型机时代的转变有几个关键因素。一是集中式的高性能计算机造价太昂贵,个人用户人手一台不现实。那么能否大家一起share?早期低速几十k的互联网根本无法提供足够的分布能力。这两个关键的因素决定了用户个人终端的出现。可以说,计算由中心转移到终端是用户对于计算的急速增长的需求和脆弱的联网能力之间矛盾无法调和的必然结果。
而到了网络技术成熟的21世纪,解决这一矛盾有了新的可能方案。那就是将计算放到远端(云端),用户减少客户端的成本。这一看似复古的模式实在有着巨大的优势。于是乎,云计算的概念一经提出,就迅速红遍全球,当然这里面也有名字起得好的因素在。
从前面的分析我们可以看出,计算模式的改变并不是某几个人或企业能决定的,根本上说还是技术水平来决定的。是的,一点都不夸张。抽象的看确实就是生产力水平决定了上层的使用模式,即生产关系。
云计算与经济
天下熙熙,皆为利来,天下攘攘,皆为利往。就在写作本文的时候,全球最大的云计算供应商amazon的数据中心出现了严重的故障,造成多家互联网客户服务受到影响,为全球云计算市场增添了一丝阴影。
确然,如果将来大家都绑到云计算上,一旦发生故障将是十分可怕的。这听起来远没有将数据放到自己本地的机器上更为安全。那么为什么云计算的发展还是喷薄如斯呢?
如果从“利”,即经济的角度去看待这一问题,会发现一些有意思的结果。
大家都知道在经济史上,货币的出现是一个经济体系进入较高阶段的重要标志。为什么货币的出现如此重要?其实不在于说减少运输成本啊,市场调控啊等等因素。这些因素也很重要,但是更为关键的在于,货币这一体系极大的解放了生产力!
是的,听起来很夸张,但事实就是如此。在货币作为物品的代替物的时候,在稳定的金融社会,货币自身实际上就代表了生产力的成果。我们运用货币,实际上就是将生产力重新整理,投入新的生产的大循环过程。虽然说,在出现货币之前,我们干的也是这件事情。但这一过程从来没有如此的方便和有效率过。离开了货币,就相当于在生产大循环的某个环节掐住了喉咙。试想,如果一个人要吃饭,就必须自己种地,一个人要吃肉,就必须自己打猎,这一的社会生产力怎么能提高?而方便交换过程的重要手段,就是货币。
更为拔高一些,就是生产关系解放生产力。
对于云计算模式同样是如此,在计算能力被集中管理的情况下,资源可以更为有效的投入到需要的地方去。用户获取计算资源更为便捷和便宜,也更加有效率。因此,云计算的出现,在经济上是一种必然。也因为如此,不同于当年的网站或现在的广告模式,云计算在网络泡沫后必然会存活下来。
当然,更深入一些,在现代金融体制里,形成垄断后的金融大鳄们利用货币的手段可以巧取豪夺,对于未来云计算的发展,是否也会有类似的事情出现呢?
云计算与数据中心
那么云计算与数据中心又有什么关系呢?在云计算时代,用户只要通过客户端告诉云端自己的需求,云端完成之后就可以将结果push给用户。这里客户端起到了简单的信息解释的作用,并没有太多技术含量,而真正的快速解决问题需要一个强大的云端。
这个云端就是数据中心。
前面说到云计算模式是看似复古的模式。很重要的一个区别就在于提供计算服务的方式。在巨型机时代一台多用户的巨型机在机房里,各个用户登录上去,自己安排好任务然后让机器执行计算。而在云计算时代,则是几十万台计算机构建的数据中心共同为用户提供服务。而且数据中心内对用户是透明的,用户甚至根本不知道也无需知道自己的任务在哪几台机器上完成。
那么,为什么要用数据中心替代大型机呢?
这个问题在网格计算发展起来的时候曾经有过一个答案——成本。巨型机的成本实在是太高了,以至于只要拿出一部分钱购买大量廉价的PC来搭建网格就能提供接近的计算能力。看起来从成本上考虑,云计算是有太大的优势。但,这并不是最根本的原因,需知为了连接这些PC,数据中心中大量的昂贵的高性能交换机占据了大部分的成本。
那么根本的原因是什么?
说到这里,我们提下著名的摩尔定律。这一定律预测了几十年的芯片产业发展,到了近些年终于不怎么灵了。单块芯片的频率已经接近制造工艺的极限,进一步提高意义不大且成本惊人。Intel等企业早早就看到了这一点,这才提出多核的概念。可以说,多核不仅仅是用户体验改善,根本上是生产工艺局限的必然。看到这里,相信不少人已经明白了。
在信息时代的今天,要成为一朵拥有大量用户的云,所提供的计算资源(和存储资源)是惊人的,这根本不是几台巨型机就能提供的,服务所需要的稳定性也不是巨型机能保障的。没有办法了只好退而求其次,用廉价的机器搭建数据中心。也正是这一模式,成就了Google、Amazon、Facebook等新兴企业。
一个关键的问题是,这一模式是否必然成立呢?
这一问题的核心在于大量低性能节点构建的数据中心能否满足我们的庞大计算需求。
大家都知道蚂蚁搬家,有的蚂蚁搬运树叶,有的蚂蚁搬运粮食,每个蚂蚁搬动的东西有限,大量的蚂蚁一起工作就能产生惊人的搬运能力。这跟云计算的模式十分相似。但是我们知道,蚂蚁搬家再厉害也很难搬动大的石块。为什么?因为石块不能被分解开,成为一只蚂蚁可以搬动的单元。
同样,云计算模式也无法解决“石块”问题。如果一个任务根本无法分解并行进行,云计算的数据中心再庞大也只有仰天长叹了。幸运的是,我们现在碰到的大部分计算问题都可以采用这样或那样的方法来分解,然后并行进行,也正是这一巧合,让云计算在我们的世界上成为了可行。
ps, 本系列的下一篇将侧重分析数据中心中的核心技术和问题,希望关注技术的同仁不要错过。
Tuesday, April 19, 2011
NSDI 2011论文选读
1、ServerSwitch: A Programmable and High Performance Platform for Data Center Networks
作者:MSRA
概述:用通用芯片为未来DCN平台提供更灵活、可编程且快速的交换,并支持流控等功能;
目前问题:软件交换仍然不够快,且延迟大;fpga-based编程复杂度高,且昂贵;
基础:通用交换芯片已经支持编程;PCI-E接口提供CPU和IO子系统之间微秒级延迟
架构
2、Efficiently Measuring Bandwidth at All Time Scales
作者:UCSD和Cisco
概述:解决细粒度的(高速)带宽抖动的测量问题;
目前方案问题:要么内存占用太多,要么是为某个粒度或目的设计,不能在全尺度上测量;
思路:提出两个算法,一是在不同尺度(指数比例)上用计数器统计,一是根据带宽动态分块,速率越高,自然需要分的块越多,在统一时间单元上块就越窄。
3、ETTM: A Scalable Fault Tolerant Network Manager
作者:University of Washington
概述:提出一种scale、fault tolerant、包粒度上的网络管理机制
目前方案问题:middle box功能单一、位置局限在网络边缘;of不支持复杂的包处理,依赖支持of的交换机
基础:交换机可控性增强、终端支持安全控件等
思路:终端安装软件,利用分布式的交互来实现逻辑上的集中控制
架构:

4、Design, Implementation and Evaluation of Congestion Control for Multipath TCP
作者:University College London
概述:为Multipath TCP提出一种流控机制
设计原则:公平性、跟目前的TCP的合作性
实验:在multihomed servers、DCN 和mobile clients中进行实验验证
5、SliceTime: A Platform for Scalable and Accurate Network Emulation
作者:RWTH Aachen University,Germany
概述:提出一套可扩展、准确的网络模拟平台,支持超过10K的节点实时模拟
目前方案问题:实时性很重要,但现有方案计算复杂性太高
设计:

Sunday, April 10, 2011
从不确定原理到存在性假设
不确定原理
“海森堡不确定性原理(英语:Heisenberg Uncertainty Principle,有時也被譯成海森堡測不準原理)是由德国物理学家海森堡于1927年提出的量子力学中的不确定性,具体指在一个量子力学系统中,一个粒子的位置和它的动量不可被同时确定。
位置的不确定性  和动量的不确定性
和动量的不确定性 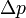 是不可避免的:
是不可避免的:
 ;
;
其中 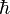 是約化普朗克常数。
是約化普朗克常数。
类似的不确定性也存在于能量和时间,角动量和角度等許多物理量之间”
-----摘自维基百科
这一原理一开始是数学推理上的产物,并在相当长的时间里无法得到一个合理的物理解释,一度被视为一种观察者效应。
实际上,不确定性原理确实很容易被理解为一种观察上局限。现有的观测技术存在着物理意义上的精度下限。例如要观测一个粒子,我们至少要依赖有其它粒子(常见的如光子)与其相互作用。对于宏观物体来说,光子不会对其产生显著可见的影响,但是到了微观粒子尺度,这一影响就不可忽视了。入射光子会明显干扰到被观测对象的行为。
这一理解往往导致一种错觉,就是真实世界其实并不存在这一局限,而只是因为我们观察手段的有限。换句话说,虽然我们无法确定它,但它在想象中应该确定的存在在那里。然而,随着量子力学的相关进展,人们越来越意识到,这种不确定性竟然跟量子力学是相容的,或者说,甚至是一个必须成立的基本假设。那么,这是否意味着我们的世界在真实意义上本身就存在某种不确定性?这一问题现在尚无人能给出一个明确可信的答案。
数十年后,其他的学者在其他一些新兴领域也发现了类似的不确定性原理,包括信息论、控制论。种种迹象似乎也都暗示着同一个假设。
系统的演化法则
我们的世界,大到宇宙,小到生物体,都是无比精密和复杂的系统。
作为新兴的21世纪的科学,系统科学的着眼点在于整体。任何系统无非包括两大因素,一是组成单元,一是组织结构。通过在不同层次上去分解,同一个系统可以被不同角度的理解和分析。而通过不同的组织原则,同样的单元可以构建不同功能的系统。
一个典型的大系统就是地球生态圈。在经历了几十亿年的演化后,地球从荒凉的无机世界逐步演变成繁荣的今日世界。而从物理角度去看,地球自身这个大实验瓶,在几十亿年里几乎是完全独立的,输入的无非是各类辐射(包括阳光)或者星尘。一个几乎封闭的系统,自身演化能到今天这个样子,不得不说是个奇迹。
达尔文说生物进化是自然选择的结果,而提供自然选择样本的根源则是各类变异。那么自然选择的法则是什么呢?变异的动力来源又是什么呢?
第一个问题达尔文曾试图利用基本的淘汰说来解释,第二个问题则没有能给出回答。
实际上,用控制论的角度去看,任何系统都动态的处在一个个状态的演变中,这些状态有些是不稳定的,在随机扰动下很快就偏离出去;有一些是相对稳定的,能够抵抗住一般的小扰动的干扰。给定足够精确的系统模型,给定足够准确的干扰序列,我们就可以预知其任何时刻所处在的状态。
利用这个观点去看生物的进化,也无非是个类似的过程。生态圈作为一个完整的系统,存在着自身的基本单元(风雷水火。。。)和组织法则(各种物理定律),在各种扰动的影响下,不断从一个稳态变化到另一个稳态。系统偏离稳态所需要的扰动往往是剧烈的,可想而知,每一次的演变引起的可能都是天翻地覆的变化,例如恐龙时代的结束。
用控制论的观点很完美的解释了生物进化的过程。然而接着来谈第二个问题,变异的动力来源(扰动)是什么?不可否认,来自地外的影响占据了一部分,但毕竟有限。更主要的扰动应该是来自内部……
是的,不要惊讶,很可能不确定性原理所表述的,正是这个世界演化到今天的根本源动力。
存在性假设
现在,我们要继续探讨的,是哲学上一个绕不开的话题。
世界是确定的还是非确定的?
这不仅仅是个饭后无聊用来消遣的哲学问题,更是个严肃的自然科学问题。
如果我们承认世界在本质上是不可确定的,概率存在的(似乎听起来符合“科学”些),那么科学的尽头已然出现了,不确定的东西按照我们的逻辑是无法去研究的。
如果世界是可确定的,真实意义上的,那么,我们其实否认了自身的存在,因为这意味着主观其实不存在,我们下一刻的任何行为都是被预设的,听起来似乎不那么容易被接受。
我们在前面的讨论中,暗示了世界低层次的存在很可能是不确定的。而宏观层次因为组织演化法则的约束,在某种意义上实际上是概率确定的。
这里就有一个很有趣的问题,人的意识应该属于微观层次还是宏观层次?或者说,人的意识是否是宇宙这个大系统自然演化状态的一个产物?如果承认了这一假设,那么就认可了带有悲观色彩的论点;而不承认这一点,又无法用现代的科学体系自圆自说。
所以,信仰宗教的人是幸福的。
一切搞不明白的事情,都可以丢给上帝。
Python 珠玑
lambda
f=lambda x,y…:exp(x,y…) //like x+y直接定义一个函数,如果调用f(x,y…),等价于获得exp(x,y…)的值
filter
filter(bool_func,[d1,d2,d3…])返回数据序列里面满足bool函数的子序列
map
map(func,[d1,d2,d3…])返回[func(d1),func(d2),func(d3)…]
reduce
reduce(func,data_seq[,init])对序列中元素迭代执行func,即每次取当前计算结果和序列中下一个元素作为执行对象
list comprehension
[expr1 for k in list if expr2]Time counting
import time.clocktime1 = time.clock()
Dosth()
time2 = time.clock()
print (time2-time1)
to be updated…
创新无处不在
何为创新?
并非要如图灵、特斯拉等大师一般开创一片崭新的天地,影响后世数百年。
用现有的技术解决别人已经解决过的问题,但是比别人做的要好、要便宜就是创新。
经常留意生活,创新的点子其实无处不在。记录下前阵琢磨出来两个可能创业的点子。
智能车窗
背景:汽车行业是蓬勃发展的一个大产业,几百年的机械技术已经成熟,下一步普通汽车也必然向着智能化、电子化的路线发展。但是除非是很高档的昂贵车型,普通汽车还难以做到智能化。但我们可以面向几个亟待解决的问题,提出几个容易实现的方案。
问题:GPS导航。没错,就是GPS导航。现在的GPS技术已经十分发达,但传统的GPS导航模块通过在一块小平板上给出虚拟的路线,然后司机来人工对应,十分不方便,且可能影响视线。
思路:为何不把GPS直接放到车窗中去呢?增强现实?如果在车窗投进的车外路况上通过叠加的方式添加GPS导航信息,例如一条绿线来实时的指引正确导航的道路,该是多么的自然,多么的COOL!
解决:考虑到实用性,几个难点,一个是要有摄像头来跟踪司机的眼睛角度,实时准确叠加;一个是如何在车窗上显示,一种方案是采用有电子元件的车窗,但造价不菲,一种是有个微型投影仪来做投影,需要考虑反射效率。简化版本甚至可以在大屏幕手机上做demo,例如iPhone,作为一小块带有显示功能的小车窗。
家庭网盘接口
背景:不知道大家有没有注意,现代的家庭环境,离不开计算机,而有计算机的家庭,往往都有一个共同的需求,就是存储管理。不少人专门弄一台老机器,挂上几块硬盘,作为家庭共享的资料服务器。
问题:用老机器来挂硬盘,不得不说是牛刀杀鸡了,不光浪费机器自身性能,而且耗电、稳定性都成问题。能否有一种便宜而方便的方案?
思路:如果我们有这么一个网盘接口,一头可以支持USB口(目前移动硬盘等的通用接口),一头支持网口,然后往交换机上一插,能自动的获取到IP(提供简易的网络访问界面来配置),问题自然解决。
解决:考虑到成本,就是一个小单片机跑一个简化版的os,大学相关专业的SRT学生都可以搞一个demo出来。主要解决的问题是io读写的问题,简化版的os如何支持好多种的磁盘格式,例如windows用户常用的fat,ntfs之类。市场上还没有类似定位产品,有提供冗余磁盘阵列解决方案的,售价都要数千元rmb,而本方案成本可以控制在百元以下,极具竞争力。
Thursday, March 17, 2011
“懒人”的革命
当慢吞吞的程序不断折磨着你的耐性,当为了找个文件用鼠标不断的点击
你是不是已经发现,计算机的处理能力发展越来越快,自己的工作效率却越来越难提高。如果你已经意识到了这点,那么恭喜你,在可能是人类历史上最大的一次革命来临之前,你已经提前窥见了依稀的曙光。
几十年来,我们始终把目光聚焦到计算机所谓的性能指标上——CPU、存储、带宽……
现在的个人计算 机的性能可以超过数十年前的巨型机,然而,那个时代的机器就已经可以让阿波罗号飞船成功登月,你的计算机理论上甚至能完美的再次模拟这个过程。那么,为什 么我们用它做日常办公用的时候,常常会被它折磨的大喊“不爽”or“郁闷”?到底影响我们日常应用计算机效率的瓶颈在什么地方?是我的操作不够快么?
好 吧,如果你足够幸运,身边有几个真正的IT牛人,你会知道,他们平时只用黑乎乎的字符界面【注1】,他们流畅的敲击着键盘,一串串劈里啪啦的指令不停的发 送到终端,他们从来不碰鼠标,甚至就没有鼠标。再如果你有幸跟他们交流,你惊奇的发现你干了一周的活,他们一天时间就轻松搞定了,于此同时他们还顺手创造 出了大量的脚本,以便下一次干类似的活的时候只用半天甚至短短几个小时。运指如飞——发挥你跟计算机最高的交流速度,这就是现在计算机时代的最高境界。
放 到结绳记事时代,这些人必定是捆绳子最快的人。他们做事情的效率很高,不是一般人能比得上的,他们往往为周围的人所敬仰和器重。如果你是这样的人,千万不 要洋洋自得;如果你不是,你可能会想,如果自己也是这样的人该多好啊,然后如果你有足够的毅力你会去努力,在“衣带渐宽”后,可能自己也会成为让人羡慕的 一员。然后你期待自己会成为能在历史上占有一席之地的“人物”。
然而,很不幸,你的愿望可能不会实现。如果你没有仔细的去 读读历史,起码是科技进步史,那么记住我的这句话——“历史会留给试图改变的人们”。如果不是某个捆绳子很慢的人觉得捆绳子太麻烦,可能现在人类会进化出 4只手来;如果不是某个懒惰的小孩觉得计算太费事,我们现在压根都不会有计算机。
不要因为你的“懒惰”,因为你的不如人而郁闷了,你感觉到了“不足”,这是你可能成为改变历史的“牛人”的第一步,下一步就是“find it”,找出可以让自己继续“懒惰”下去的方法。
办公室里面的人们往往是很勤劳很勤劳的,我不止一次的见识到用“一指禅”神功耐心录入的人,我也不止一次碰见为了找个运行程序一层层点开七八层菜单的人,我更是不止一次的看到那么多新鲜年轻的面孔,他们抱着一堆堆“技巧”、“专家”字样的垃圾书津津有味的品读着。
以这样的方式,再高效的操作,实际的工作效率只能是个零头。
好吧,让我们尝试着改变一点,提高我们工作效率的数量级吧。
即 使你是windows的用户,仍然有一堆的小玩意可以让你的效率成倍的提高(包括launchy、hoekey、Gvim……),简单的try一下,你就 能体会到你以前过的是多么不能让人容忍的生活,简单的把它们分享给周围的人,你就能真正体会到一个高效的环境是多么的让人愉悦。
这个改变够大了么?它已经足够让你成为工作一族中的效率佼佼者,但是,它还不足以让你成为一场大革命的缔造者。
如 果你足够“懒惰”,想必会有这样的疑问,为什么不干脆抛弃慢腾腾的键盘和鼠标呢?为什么不直接用嘴巴告诉计算机:“帮我查查天安门到望京大厦的路线”,甚 至是“写一篇关于火星人古文明的论文”,再夸张一点,就像matrix里面的,直接用思维跟计算机进行交流(现在有做bci的,希望能早点实用起来)。那 样的交流效率已经不是今天可以想象的了。人的生命也会被延伸。。。
这个预言并不过早,我们已经处在了这场革命的开头,“懒人们”,为了捍卫“懒惰”,去开创崭新的时代吧!
【注1】如果因为这点,你得以的去show你windows(or vista)的桌面效果,你会后悔的,起了x开启效果后的ubuntu(其他的linux自然也可以装),已经可以跟mac媲美,更何况公认土土的windows
【注2】本文完成于2008年。
你是不是已经发现,计算机的处理能力发展越来越快,自己的工作效率却越来越难提高。如果你已经意识到了这点,那么恭喜你,在可能是人类历史上最大的一次革命来临之前,你已经提前窥见了依稀的曙光。
几十年来,我们始终把目光聚焦到计算机所谓的性能指标上——CPU、存储、带宽……
现在的个人计算 机的性能可以超过数十年前的巨型机,然而,那个时代的机器就已经可以让阿波罗号飞船成功登月,你的计算机理论上甚至能完美的再次模拟这个过程。那么,为什 么我们用它做日常办公用的时候,常常会被它折磨的大喊“不爽”or“郁闷”?到底影响我们日常应用计算机效率的瓶颈在什么地方?是我的操作不够快么?
好 吧,如果你足够幸运,身边有几个真正的IT牛人,你会知道,他们平时只用黑乎乎的字符界面【注1】,他们流畅的敲击着键盘,一串串劈里啪啦的指令不停的发 送到终端,他们从来不碰鼠标,甚至就没有鼠标。再如果你有幸跟他们交流,你惊奇的发现你干了一周的活,他们一天时间就轻松搞定了,于此同时他们还顺手创造 出了大量的脚本,以便下一次干类似的活的时候只用半天甚至短短几个小时。运指如飞——发挥你跟计算机最高的交流速度,这就是现在计算机时代的最高境界。
放 到结绳记事时代,这些人必定是捆绳子最快的人。他们做事情的效率很高,不是一般人能比得上的,他们往往为周围的人所敬仰和器重。如果你是这样的人,千万不 要洋洋自得;如果你不是,你可能会想,如果自己也是这样的人该多好啊,然后如果你有足够的毅力你会去努力,在“衣带渐宽”后,可能自己也会成为让人羡慕的 一员。然后你期待自己会成为能在历史上占有一席之地的“人物”。
然而,很不幸,你的愿望可能不会实现。如果你没有仔细的去 读读历史,起码是科技进步史,那么记住我的这句话——“历史会留给试图改变的人们”。如果不是某个捆绳子很慢的人觉得捆绳子太麻烦,可能现在人类会进化出 4只手来;如果不是某个懒惰的小孩觉得计算太费事,我们现在压根都不会有计算机。
不要因为你的“懒惰”,因为你的不如人而郁闷了,你感觉到了“不足”,这是你可能成为改变历史的“牛人”的第一步,下一步就是“find it”,找出可以让自己继续“懒惰”下去的方法。
办公室里面的人们往往是很勤劳很勤劳的,我不止一次的见识到用“一指禅”神功耐心录入的人,我也不止一次碰见为了找个运行程序一层层点开七八层菜单的人,我更是不止一次的看到那么多新鲜年轻的面孔,他们抱着一堆堆“技巧”、“专家”字样的垃圾书津津有味的品读着。
以这样的方式,再高效的操作,实际的工作效率只能是个零头。
好吧,让我们尝试着改变一点,提高我们工作效率的数量级吧。
即 使你是windows的用户,仍然有一堆的小玩意可以让你的效率成倍的提高(包括launchy、hoekey、Gvim……),简单的try一下,你就 能体会到你以前过的是多么不能让人容忍的生活,简单的把它们分享给周围的人,你就能真正体会到一个高效的环境是多么的让人愉悦。
这个改变够大了么?它已经足够让你成为工作一族中的效率佼佼者,但是,它还不足以让你成为一场大革命的缔造者。
如 果你足够“懒惰”,想必会有这样的疑问,为什么不干脆抛弃慢腾腾的键盘和鼠标呢?为什么不直接用嘴巴告诉计算机:“帮我查查天安门到望京大厦的路线”,甚 至是“写一篇关于火星人古文明的论文”,再夸张一点,就像matrix里面的,直接用思维跟计算机进行交流(现在有做bci的,希望能早点实用起来)。那 样的交流效率已经不是今天可以想象的了。人的生命也会被延伸。。。
这个预言并不过早,我们已经处在了这场革命的开头,“懒人们”,为了捍卫“懒惰”,去开创崭新的时代吧!
【注1】如果因为这点,你得以的去show你windows(or vista)的桌面效果,你会后悔的,起了x开启效果后的ubuntu(其他的linux自然也可以装),已经可以跟mac媲美,更何况公认土土的windows
【注2】本文完成于2008年。
Internet: Clean Slate vs Evolution
互联网的clean slate (清白历史?) 和 evolution (演进)之争由来已久。
当今的互联网在设计之初并未考虑到后世会发展到如此大规模,有如此多的应用,占据人类社会如此重要的地位。即使是在现在和可以预见的未来,都很难再找出第二个事物来与之相提并论。随着技术的发展和规模的增加,互联网逐渐浮现出一些难以解决的问题,包括管理、分发、计费、扩展等等。
于是学术界提出了clean slate的想法,基本出发点是放弃原有的设计,去掉一切限制,重新设计架构。这些年也着实作出了不少的成果。另一方面的观点认为,我们应该采取逐步演化的方式,在原有架构上缝缝补补,慢慢改进。可以看出前者带有明显的理想主义色彩,属于学院派风格。后者则更为实用,属于工业界的观点。
其实,这两派观点的出现并非偶然。对于学术界来说,标准的思路是研究人员制定好标准,工程师来将它实现。而互联网从一开始就缺乏一个统一主导的管理者角色,是通过各种技术的竞争演变而来。因此,技术的实用性、代价和反应速度等都很关键。工业界并不在乎某个设计是否ugly,至少它能很快的工作起来,那么就有很大的几率被部署和推广。对于Clean Slate来说,需要花费太大的代价进行迁移。牵扯利益太多,几乎是不可能的,所以只能是作为学术界研讨的课题。
因此,从根本上说,现代互联网,是无统一管理(NGO)的产物,正因为它的发展太过迅速,来不及让人来思考或等待,还没有想好谁来管,它就已经开始运行了。但正如我此前的观点,产业的成熟必然催化垄断。在互联网产业,也已经隐隐有此兆头。学术界,甚至在工业界,技术、标准、监管都已经开始统一化、垄断化。未来的互联网很可能具有极强的管理性,到那时,Clean Slate或许将成为可行。
当今的互联网在设计之初并未考虑到后世会发展到如此大规模,有如此多的应用,占据人类社会如此重要的地位。即使是在现在和可以预见的未来,都很难再找出第二个事物来与之相提并论。随着技术的发展和规模的增加,互联网逐渐浮现出一些难以解决的问题,包括管理、分发、计费、扩展等等。
于是学术界提出了clean slate的想法,基本出发点是放弃原有的设计,去掉一切限制,重新设计架构。这些年也着实作出了不少的成果。另一方面的观点认为,我们应该采取逐步演化的方式,在原有架构上缝缝补补,慢慢改进。可以看出前者带有明显的理想主义色彩,属于学院派风格。后者则更为实用,属于工业界的观点。
其实,这两派观点的出现并非偶然。对于学术界来说,标准的思路是研究人员制定好标准,工程师来将它实现。而互联网从一开始就缺乏一个统一主导的管理者角色,是通过各种技术的竞争演变而来。因此,技术的实用性、代价和反应速度等都很关键。工业界并不在乎某个设计是否ugly,至少它能很快的工作起来,那么就有很大的几率被部署和推广。对于Clean Slate来说,需要花费太大的代价进行迁移。牵扯利益太多,几乎是不可能的,所以只能是作为学术界研讨的课题。
因此,从根本上说,现代互联网,是无统一管理(NGO)的产物,正因为它的发展太过迅速,来不及让人来思考或等待,还没有想好谁来管,它就已经开始运行了。但正如我此前的观点,产业的成熟必然催化垄断。在互联网产业,也已经隐隐有此兆头。学术界,甚至在工业界,技术、标准、监管都已经开始统一化、垄断化。未来的互联网很可能具有极强的管理性,到那时,Clean Slate或许将成为可行。
Thursday, March 10, 2011
互联网的社会史
今天跟朋友聊天,无意中说到互联网产业的发展历史,感觉跟人类社会的历史发展有颇多共同之处。
马克思所说的“生产力决定生产关系”,看起来很简单,却一语道破人类社会发展的根本规律。对于自然科学来说,能够看穿复杂的事物表面,准确把握内在规律,这绝对是大师级人物才能做到;而对更为复杂的社会科学做到这一点,古往今来,不过寥寥数人。马克思能被评为“千年思想家”这不是巧合,绝对是名副其实的。
借用这一观点,互联网产业的发展,根本上是由各个阶段的生产力水平——也即IT技术水平来决定的。
在最初的阶段(实验到DARPA时代,60年代及以前),网络规模小、链路带宽低、用途目的简单,正像是原始社会的部落制度。各个小网之间甚至网络内部联系都十分松散,应用是傻大粗的奔放模式,更多的是作为试验品,缺乏高级的应用。
第二个阶段(70年代~80年代)是TCP/IP的发展和成熟以及一些应用开始出现,包括telnet、UseNet、email等等。这些应用就好比是种植业的出现,使得互联网的实用性和效率都有了显著的提高。同时,互联网仍然是集中在少数国家,集中性相当明显。类似于奴隶制下的集中低效生产模式。
第三个阶段(80~2000年代)则是互联网的进一步普及,美洲、欧洲、亚洲不少大学和科研机构纷纷接入网络,网络规模进一步扩大,DNS出现,NSFnet建成,并由实验网转入商业运营。www协议的出现更是极大的促进了网络的普及。相关机构成立,互联网的管理由几大组织(IETF等)和几大运营商来负责。类似于封建制下严格的等级管理模式。
第四个阶段(2000年至今),互联网相关技术进一步成熟并趋向稳定,创新的大浪潮已经过去,难以出现革命性的变化,新出现的应用多是改进和扩展。云计算相关技术的发展让资源进一步集中,利益划分更为明确。物理链路牢牢掌握在各个政权手中,而垄断的运营商们之间相互竞争和合作,各国对网络上运行的数据信息监控力度加大,现有模式下有大的变化已经毫无可能,正是当今世界凑综复杂制衡格局的极好展现。
总体来说,互联网的出现,极大打破了传统行业中的层级和垄断模式,让无数“平民”等级可以凭借智慧和努力在产业链上分得一勺羹。但随着技术的提高以及网络应用的成熟,互联网的重要性对各个国家都不言而喻,相关的监控或管理力度必然会进一步加大。在互联网产业越来越成熟的今天,想要挤占一方市场将会越来越困难。
马克思所说的“生产力决定生产关系”,看起来很简单,却一语道破人类社会发展的根本规律。对于自然科学来说,能够看穿复杂的事物表面,准确把握内在规律,这绝对是大师级人物才能做到;而对更为复杂的社会科学做到这一点,古往今来,不过寥寥数人。马克思能被评为“千年思想家”这不是巧合,绝对是名副其实的。
借用这一观点,互联网产业的发展,根本上是由各个阶段的生产力水平——也即IT技术水平来决定的。
在最初的阶段(实验到DARPA时代,60年代及以前),网络规模小、链路带宽低、用途目的简单,正像是原始社会的部落制度。各个小网之间甚至网络内部联系都十分松散,应用是傻大粗的奔放模式,更多的是作为试验品,缺乏高级的应用。
第二个阶段(70年代~80年代)是TCP/IP的发展和成熟以及一些应用开始出现,包括telnet、UseNet、email等等。这些应用就好比是种植业的出现,使得互联网的实用性和效率都有了显著的提高。同时,互联网仍然是集中在少数国家,集中性相当明显。类似于奴隶制下的集中低效生产模式。
第三个阶段(80~2000年代)则是互联网的进一步普及,美洲、欧洲、亚洲不少大学和科研机构纷纷接入网络,网络规模进一步扩大,DNS出现,NSFnet建成,并由实验网转入商业运营。www协议的出现更是极大的促进了网络的普及。相关机构成立,互联网的管理由几大组织(IETF等)和几大运营商来负责。类似于封建制下严格的等级管理模式。
第四个阶段(2000年至今),互联网相关技术进一步成熟并趋向稳定,创新的大浪潮已经过去,难以出现革命性的变化,新出现的应用多是改进和扩展。云计算相关技术的发展让资源进一步集中,利益划分更为明确。物理链路牢牢掌握在各个政权手中,而垄断的运营商们之间相互竞争和合作,各国对网络上运行的数据信息监控力度加大,现有模式下有大的变化已经毫无可能,正是当今世界凑综复杂制衡格局的极好展现。
总体来说,互联网的出现,极大打破了传统行业中的层级和垄断模式,让无数“平民”等级可以凭借智慧和努力在产业链上分得一勺羹。但随着技术的提高以及网络应用的成熟,互联网的重要性对各个国家都不言而喻,相关的监控或管理力度必然会进一步加大。在互联网产业越来越成熟的今天,想要挤占一方市场将会越来越困难。
Thursday, February 24, 2011
如何让你的“水果”更值钱?

有个很经典的营销学故事,具体细节已经不记得了,下面是我个人演绎的版本。
----------------------------------故事开始------------------------------------
说课堂上,大牌教授掏出一个普通的苹果,问大家,如何卖1块钱?10块钱呢?100块……甚至100万!
卖1块钱,很简单,洗得干干净净的摆在超市,自然会有人买。
10块钱?也不难,例如,我们可以做成水果拼盘或者榨成果汁,在餐厅里也会有人购买。
100块开始就有点难度了。同学们仍然纷纷提出各种主意,例如宣称“这是一个转基因苹果,营养十分的丰富”、“这个苹果曾被带到太空中中”、“这个苹果上有明星的签名”……
100万呢?热闹的课堂一下子鸦雀无声。这太疯狂了,一个本来只值1块钱的苹果,怎么能卖出100万倍呢?
教授等了几分钟后,还是没人回答。缓缓说道:“这是当年砸到牛顿的那个苹果,将由英国女王亲自主持拍卖,筹集到款项将用于拯救饥饿中的非洲儿童,拍到者将被授予爵士勋章……全球仅此一个,底价100万!”
一下子,课堂有热闹起来了,同学们纷纷嚷道“100万?太便宜了!起码能值1000万!”
----------------------------------故事结束------------------------------------
这个故事自然夸张荒诞,相信看到的同学都会一笑了之。然而,类似的故事却在每天不断上演。
几乎同样的配置,IBM当年ThinkPad系列的笔记本要比其他品牌的贵出30%,甚至更多。
凛冽的寒风中,长长的队伍,只是为了一款成本价只有售价1/N的手机;
普通域名注册一年仅需要十几块钱,而某域名去年年底被卖出1300万美金的天价;
就在几年前,一只明朝青花瓷瓶被拍出上亿元的天价;
房子、石油、黄金……
类似的事例在生活中几乎随处可见。
一般情况下,物品的价格由价值决定。那么,到底是什么造成了升值?是需求?是品牌?是炒作?还是大家真的都疯了?
在原始社会,人都是通过打猎为生,相互之间的交换基本上以成本(很大程度上是重量,体型大的动物不仅可以提供更多的热量,也往往意味着更多的平均捕获时间)作为唯一衡量标准。在吃饱饭是第一要务的情况下,几乎没有人愿意花费时间去做除了努力生存下去的其他事情,更没有可能有其他复杂的交易理念。
很快,随着生产力提高,社会分工自然出现,事情就变得有趣起来。一方面,个人不必再把大量事件花费在维持生存上,自然就有了更多更高的需求,例如吃饱了饭之余,还希望能吃点水果帮助消化;另一方面,同样的工种之间开始出现了竞争。同样都是种苹果的水果商,我家的苹果个大还好吃,大家就愿意拿出更多的钱来买(在这里,先不讨论充满了欺诈和无耻的西方金融骗局)。于是,第一个影响价格的重要因素就出现了,那就是质量。质量好的,就更值钱!
社会的发展是飞速的。人的需求发展也是飞速的。有聪明的人发现,把苹果轧成果汁更好喝,而且还省时省力。还有人发现,人们不但喜欢吃苹果,还希望有机会尝尝其他口味的水果,特别是比较少见的稀有的水果。聪明的水果商于是宣布,提供更高级的水果产品,不仅包括洗干净、包装好的完整水果,还提供水果汁、水果酱……等一系列产品。并且,为了满足大家的口味需求,还将从遥远的国度运来大家从未听说过的水果品种,购买者还能得到去皮去核的服务。当然,这个价格嘛,要适当的涨涨。对此,大家也都选择了接受。虽然不喜欢花钱,但为了更好的服务享受,多花点钱也是值得的。因此,服务可以提升价格。
交通的发展极大促进了商业的发展。聪明的水果商人们发现不同地区的人们对于水果的需求是不同的,愿意为之掏的钱也是不一样的。为了赚到更多的钱,我们不能光呆在一个地方。水果商们唱着小曲开开心心地四处拓宽市场。一个新的问题出现了。到了一个新的地方,水果商需要付出大量时间和代价让人们认识自己的产品。但过些年再回来,可能新的人们就不知道自己了。反反复复,水果商伤透了脑筋。于是有聪明人想出了个点子,我们每家水果商都起个代号吧。毕竟,人们记住代号要比记住水果商本身简单一些。于是,品牌出现了。优秀水果商的品牌被人们牢记,并被四处宣传,他们的水果也就容易卖出。新出现的水果商要想卖出水果,需要花出更多的代价。于是,各个水果商为了提升自己的品牌影响力,纷纷使出各路神通,明星代言、慈善活动、各种广告……可见,品牌是提升价格的重要因素。
人的欲望是没有限制的,商人赚取利润的天性也是没有极限的。大的水果生产商每天都在琢磨怎么才能赚取更多的钱。他们通过观察发现,小水果商因为成本有限,往往无力去运输极远地区的稀有水果。于是,大水果商决定联合起来,成立一个“保护稀有水果维持公平竞争联盟”。联盟内部成员统一运输和贩卖稀有水果,联盟外成员不允许贩卖,否则将被处以重罚。小水果商要想加入联盟,很简单,需要每年缴纳“会员费”。小水果商打掉牙往肚里咽,缴纳了会员费的拣点边缘利润,缴纳不起的只好宣布破产或转行了。到了这一步,大水果商终于可以高枕无忧了。实际上,垄断是自由定价的唯一先决。
好了,分析到这里,已经可以回答大部分的问题了。IBM、Apple之类的大生产商,东西比别家贵,无他,质量、服务是很重要的因素,品牌跟垄断也是不可忽视的。同样的道理,其实也适用于各行各业。一般来说,质量是实在的,也是难以短期内体会或比较到的。形成垄断,对于普通企业来说,更是难以实现的。因此,服务跟品牌这两大虚拟价值,就成了信息时代里相互竞争十分关键的因素。而这两者的根本都在于用户体验。当我们点开一家公司的网页,惊奇地发现页面设计毫无美感,技术毫无规范(例如仅支持IE、gb2312编码等),我们就知道,这家公司其实并不在乎它的服务跟品牌,并不在乎它的用户(特别表现在用户体验);同样的,当我们拿到一个申请人的简历,发现布局混乱、信息极难获取的时候,我们也会不自觉的认为这个人不尊重这个申请,甚至将其直接忽略。如果你还有所怀疑的话,可以去留心成功企业的宣传和所作所为。
是的,这就是让水果增值的所有秘密。如果阅读后你觉得自己懂得了点什么,那么无论是不是一个企业家,每天睡觉前都可以尝试问问自己——
今天,你的水果更值钱了么?
NOX -- 现代网络操作系统
[注]本系列前面的三篇文章中,介绍了软件定义网络(SDN)的基本概念和相关平台。按照SDN的观点,网络的智能/管理实际上是通过控制器来实现的。本篇将介绍一个代表性的控制器实现——NOX。
现代大规模的网络环境十分复杂,给管理带来较大的难度。特别对于企业网络来说,管控需求繁多,应用、资源多样化,安全性、扩展性要求都特别高。因此,网络管理始终是研究的热点问题。
同样的情况出现在现代的网络管理中,管理者的各种操作需要跟底层的物理资源直接打交道。例如通过ACL规则来管理用户,需要获取用户的实际IP地址。更复杂的管理操作甚至需要管理者事先获取网络拓扑结构、用户实际位置等。随着网络规模的增加和需求的提高,管理任务实际上变成巨大的挑战。
而NOX则试图从建立网络操作系统的层面来改变这一困境。网络操作系统(Network Operating System)这个术语早已经被不少厂家提出,例如Cisco的IOS、Novell的NetWare等。这些操作系统实际上提供的是用户跟某些部件(例如交换机、路由器)的交互,因此称为交换机/路由器操作系统可能更贴切。而从整个网络的角度来看,网络操作系统应该是抽象网络中的各种资源,为网络管理提供易用的接口。
一是集中的编程模型。开发者不需要关心网络的实际架构,在开发者看来整个网络就好像一台单独的机器一样,有统一的资源管理和接口。
二是抽象的开发模型。应用程序开发需要面向的是NOX提供的高层接口,而不是底层。例如,应用面向的是用户、机器名,但不面向IP地址、MAC地址等。

类似的项目包括SANE、Ethane、Maestro、onix、difane等,有兴趣的同学可以进一步研究参考。
现代大规模的网络环境十分复杂,给管理带来较大的难度。特别对于企业网络来说,管控需求繁多,应用、资源多样化,安全性、扩展性要求都特别高。因此,网络管理始终是研究的热点问题。
从操作系统到网络操作系统
早期的计算机程序开发者直接用机器语言编程。因为没有各种抽象的接口来管理底层的物理资源(内存、磁盘、通信),使得程序的开发、移植、调试等费时费力。而现代的操作系统提供更高的抽象层来管理底层的各种资源,极大的改善了软件程序开发的效率。同样的情况出现在现代的网络管理中,管理者的各种操作需要跟底层的物理资源直接打交道。例如通过ACL规则来管理用户,需要获取用户的实际IP地址。更复杂的管理操作甚至需要管理者事先获取网络拓扑结构、用户实际位置等。随着网络规模的增加和需求的提高,管理任务实际上变成巨大的挑战。
而NOX则试图从建立网络操作系统的层面来改变这一困境。网络操作系统(Network Operating System)这个术语早已经被不少厂家提出,例如Cisco的IOS、Novell的NetWare等。这些操作系统实际上提供的是用户跟某些部件(例如交换机、路由器)的交互,因此称为交换机/路由器操作系统可能更贴切。而从整个网络的角度来看,网络操作系统应该是抽象网络中的各种资源,为网络管理提供易用的接口。
实现技术探讨
模型
NOX的模型主要包括两个部分。一是集中的编程模型。开发者不需要关心网络的实际架构,在开发者看来整个网络就好像一台单独的机器一样,有统一的资源管理和接口。
二是抽象的开发模型。应用程序开发需要面向的是NOX提供的高层接口,而不是底层。例如,应用面向的是用户、机器名,但不面向IP地址、MAC地址等。
通用性
正如计算机操作系统本身并不实现复杂的各种软件功能,NOX本身并不完成对网络管理任务,而是通过在其上运行的各种“应用”(Application)来实现具体的管理任务。管理者和开发者可以专注到这些应用的开发上,而无需花费时间在对底层细节的分析上。为了实现这一目的,NOX需要提供尽可能通用(General)的接口,来满足各种不同的管理需求。架构
组件
下图给出了使用NOX管理网络环境的主要组件。包括交换机和控制(服务)器(其上运行NOX和相应的多个管理应用,以及1个Network View),其中Network View提供了对网络物理资源的不同观测和抽象解析。注意到NOX通过对交换机操作来管理流量,因此,交换机需要支持相应的管理功能。此处采用支持OpenFlow的交换机。
操作
流量经过交换机时,如果发现没有对应的匹配表项,则转发到运行NOX的控制器,NOX上的应用通过流量信息来建立Network View和决策流量的行为。同样的,NOX也可以控制哪些流量需要转发给控制器。多粒度处理
NOX对网络中不同粒度的事件提供不同的处理。包括网包、网流和Network View等。应用实现
NOX上的开发支持Python、C++语言,NOX核心架构跟关键部分都是使用C++实现以保证性能。代码可以从http://www.noxrepo.org获取,并遵循GPL许可。系统库
提供基本的高效系统库,包括路由、包分类、标准的网络服务(DHCP、DNS)、协议过滤器等。相关工作
NOX项目主页在http://noxrepo.org。类似的项目包括SANE、Ethane、Maestro、onix、difane等,有兴趣的同学可以进一步研究参考。
Saturday, February 19, 2011
欢迎大家参加HostView计划
帮别人宣传一下。
项目主页:http://cmon.lip6.fr/EMD/Home.html
项目介绍:HostView是法国CNRS and UPMC巴黎大学LIP6实验室的Renata Teixeira及其学生发起的项目,通过在线采集用户的网络状态信息跟用户反馈的部分体验信息来找出网络中影响性能的因素。所有收集到的信息均会被匿名化处理,保护用户隐私。
目前,HostView提供Mac版本跟Linux版本。此外,前100个参与1个月的用户将有机会获得50$的amazon购物卡。
下载地址:http://cmon.lip6.fr/EMD/Download.html
用户手册:http://cmon.lip6.fr/EMD/Download_files/user-manual_Linux.pdf
Linux用户在下载源代码并解压后,可以通过下面的步骤安装
1 检查依赖
执行 ./checkreqs.pl
如果不满足安装依赖,会提示安装缺少的包
2 配置编译
./configure;
make
3 设置权限
./SetPermissions
4 运行程序
./HostView
项目主页:http://cmon.lip6.fr/EMD/Home.html
项目介绍:HostView是法国CNRS and UPMC巴黎大学LIP6实验室的Renata Teixeira及其学生发起的项目,通过在线采集用户的网络状态信息跟用户反馈的部分体验信息来找出网络中影响性能的因素。所有收集到的信息均会被匿名化处理,保护用户隐私。
目前,HostView提供Mac版本跟Linux版本。此外,前100个参与1个月的用户将有机会获得50$的amazon购物卡。
下载地址:http://cmon.lip6.fr/EMD/Download.html
用户手册:http://cmon.lip6.fr/EMD/Download_files/user-manual_Linux.pdf
Linux用户在下载源代码并解压后,可以通过下面的步骤安装
1 检查依赖
执行 ./checkreqs.pl
如果不满足安装依赖,会提示安装缺少的包
2 配置编译
./configure;
make
3 设置权限
./SetPermissions
4 运行程序
./HostView
Wednesday, February 16, 2011
RSA2011会展观记
相信IT安全领域的人对于RSA大会都不陌生。自1991年首次举行以来,RSA大会影响越来越大,规模也越来越大,现在已经成为IT安全领域名副其实的最吸引人的大会。近几年RSA会议的举办地点都是在旧金山湾区,吸引了大批来自世界各地的安全提供商、学者、爱好者参加。今年的举办地点是旧金山的Moscone中心,恰逢其20周年,会议长达5天(2.14~2.18)。感兴趣的读者可以从RSA网站上了解到具体的日程信息。
自1995年开始,RSA大会每年都有一个主题,今年的主题是“The Adventure of Alice&Bob”,安全的味道颇为浓厚。包括Cisco、Juniper、Palo Alto Networks等数百家知名企业均参与了会展。尤为值得一提的是,国内的NSFocus(绿盟)、TopSec(天融信)和新兴的HillStone(山石)等公司也分别携产品参展,吸引了不少目光(这才是民族的骄傲,年轻人的榜样)。总体来看,云计算的痕迹到处可见,Facebook跟Twitter很受安全厂商重视。另外,网关类安全产品在提到性能时基本上都是100G以上。
除了在大厅中进行的会展之外,还有几十个专门的技术类讲座。几乎设计所有安全热点问题,包括云、P2P、加密等等。
下面是在展会现场拍到的一些场面。

一直忙忙碌碌的Registration Desk。


Cisco跟Juniper今年看起来十分低调,位置极佳,但不是那么热闹。


Paloalto Networks位置也不错,关于NGFW的讲解十分风趣,吸引了大量的人气。

绿盟准备很充分。

山石团队,干劲十足的小伙子们。

别具一格的中关村联盟。中国人走的很不容易啊。


EMC跟VMware“心有灵犀”地大炒云跟虚拟化。

CVM也吸引了大批眼光。


美女助阵是大多数展台的统一伎俩。


吸引眼光的另一伎俩是抽奖——奖品不约而同的都是IPad。

电视台现场搭了直播棚。
下面是部分其他参展企业的情形。












Subscribe to:
Posts (Atom)